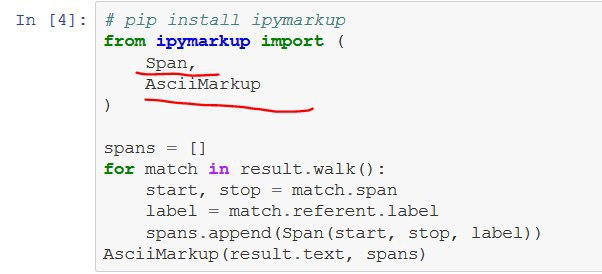
Раз уж такие дела, мне нужно извлекать имена-фамилии-отчества русские, но есть один нюанс: текст с распознавания речи, так что они могут перемежаться всякими "ммммм". Наташа что-то не очень. Пробовал 🤗, он захватывает междометия, мб придется пост писать просто. (Кстати, всем привет, первый раз отписываюсь тут 👋)
Я на SDK Pullenti делал похожую задачу, когда нужно было по введённым в поле ФИО выделить, где что. Там могли быть и ошибки, и вставки мусора. Использовал возможности не полноценного NER по выделению сущностей, а конкретно класса PersonItemToken - выделял токены, которые могут быть кандидатами на ф.и.о., и на этом принимал решение.