MB
у меня CDH, на нём репликация настроена. И она снепшоты делает но не чистит иногда, почемуто
Size: a a a
MB
MB
S
А
M
hdfs -ls -a?M
MB
MB
MB
FL
FL
GP
АЖ
FL
FL
A
YI
А
А
D
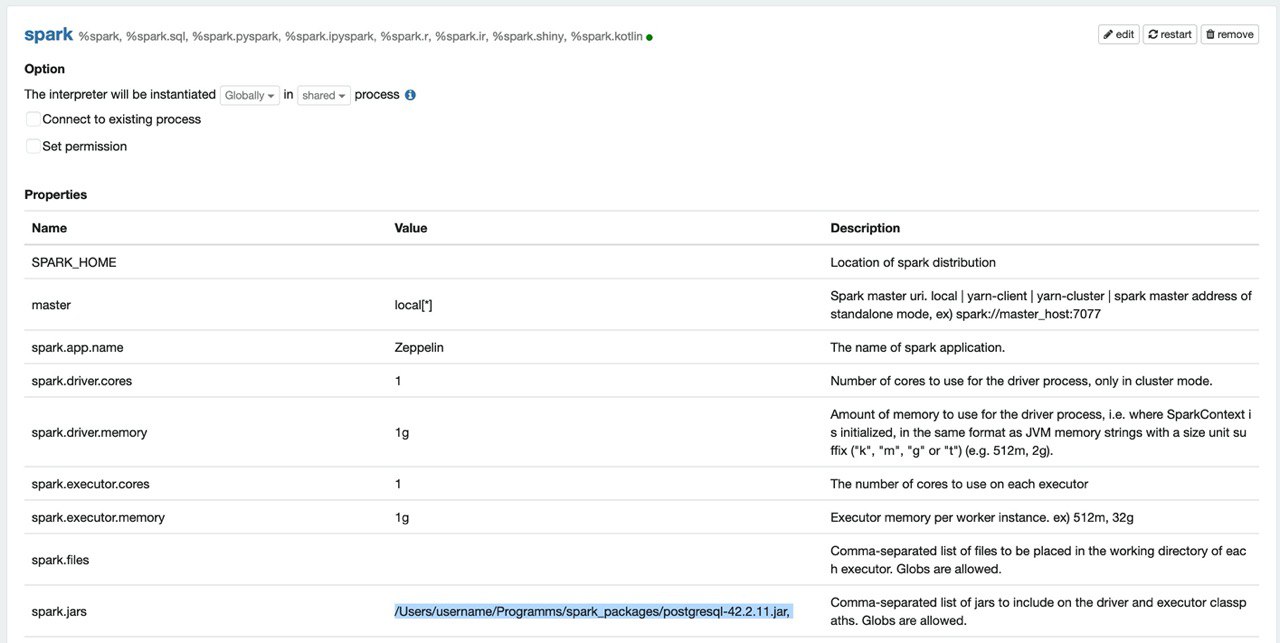
org.apache.zeppelin.interpreter.InterpreterException: org.apache.zeppelin.interpreter.InterpreterException: Fail to open SparkInterpreter