D
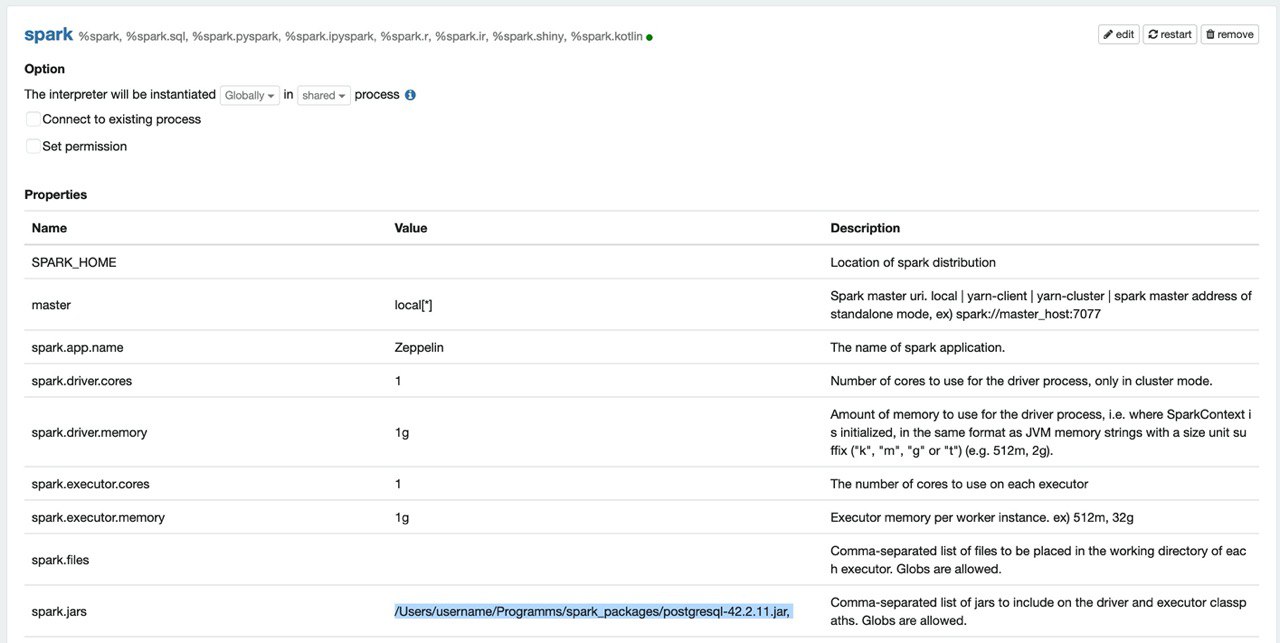
В целом, в Zeppelin, в интерпретаторе Spark, в пункте spark.jars (Comma-separated list of jars to include on the driver and executor classpaths. Globs are allowed.) добавила строку
/Users/username/Programms/spark_packages/postgresql-42.2.11.jar, и сохранила