



SA
Size: a a a
2021 January 21
SA
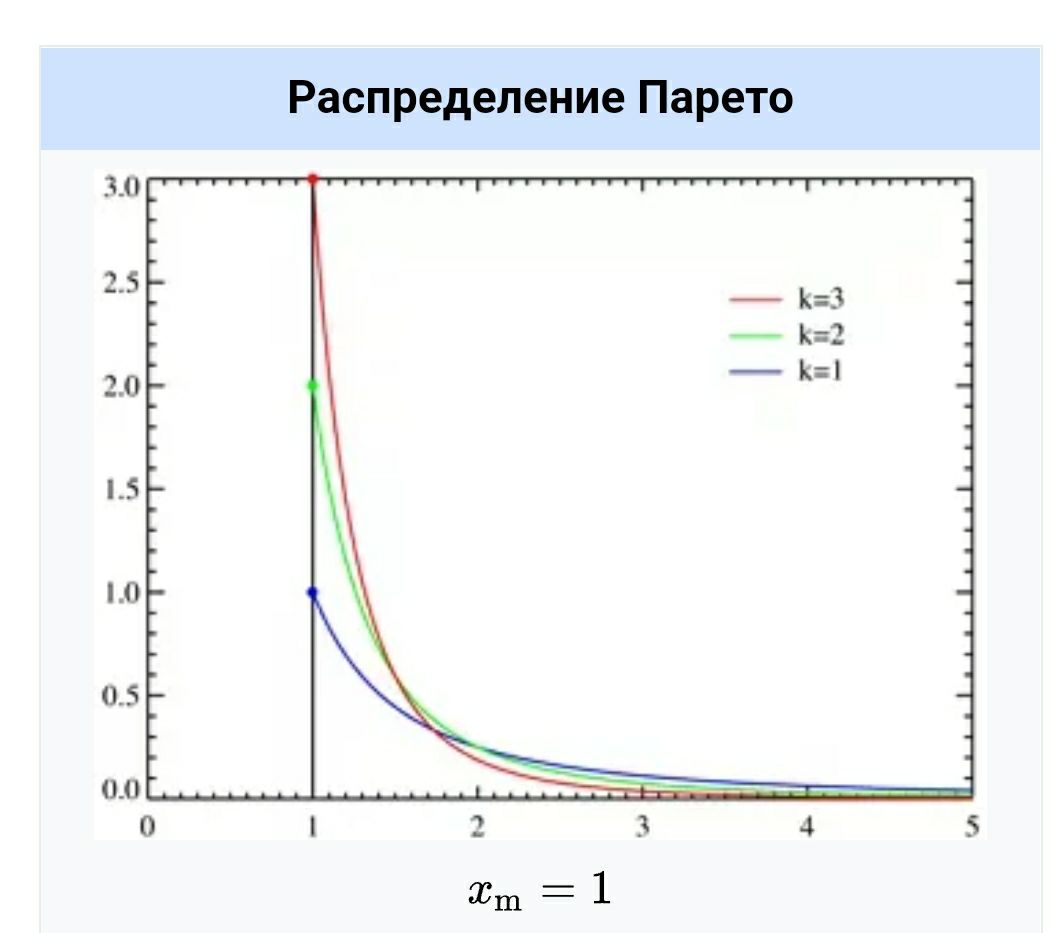
Чем больше b, тем круче график
SA
Да, спасибо, почему-то это распределение генерирует более ожидаемые результаты
Потому что это Парето.
А то, что вы выбрали -не совсем
А то, что вы выбрали -не совсем
AB
Всем привет, RandomForestClassifier мультикласс что бы получить probas на выходе, он усредняет значение probas по всем деревьям? Или там какой-то умнее алгоритм?
K
Всем привет, RandomForestClassifier мультикласс что бы получить probas на выходе, он усредняет значение probas по всем деревьям? Или там какой-то умнее алгоритм?
Усреднение. Это же случайный лес
i
Что за пробас
i
Это белорусский?
K
AB
Это белорусский?
английский, получается
V
Белорунглиш
DP
Всем привет, RandomForestClassifier мультикласс что бы получить probas на выходе, он усредняет значение probas по всем деревьям? Или там какой-то умнее алгоритм?
Есть два подхода - усреднять вероятности или усреднять решения
AB
Есть два подхода - усреднять вероятности или усреднять решения
Понял, спасибо
DP
Правильнее усреднять решения, ибо у различных деревьев вероятности могут по-разному трактоваться
DP
но вроде в реальности отличий особых нет
ЕО
Подскажите пожалуйста, когда нужно делать get_dummies(), а когда это очень вредит?
AR
Егор Овчинников
Подскажите пожалуйста, когда нужно делать get_dummies(), а когда это очень вредит?
Когда категориальный признак порядковый (холодно, тепло, горячо), их можно закодировать одним признаком (-1, 0, 1), так как значения можно поставить по порядку.
Если значений немного, то не страшно использовать get_dummies. Если значений очень много, то get_dummies создаст и много фич, что приведет к большой размерности: тут уже можно как-то группировать фичи (к примеру, редкие значения кодировать одним битом)
Если значений немного, то не страшно использовать get_dummies. Если значений очень много, то get_dummies создаст и много фич, что приведет к большой размерности: тут уже можно как-то группировать фичи (к примеру, редкие значения кодировать одним битом)
SA
Использую генпарето с одним параметром(код выше). А какой у вас размер параметра был, не подскажете?
Спасибо
Спасибо
я брала равное 5
IS
#C2W1 почему в формуле ошибки в ноутбуке Linreg_height_weight не стоит 1/n перед суммой: http://joxi.ru/eAO48qjUkQjbPr ?
При больших n ошибка растёт...
При больших n ошибка растёт...
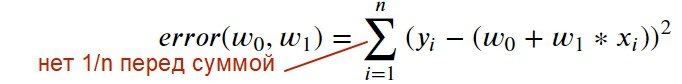
i
если вы минимизируете ошибку то положительная константа для поиска минимума не так важна
GW
есть керас моделька и два варианта вызова:
1) actions = self._model.predict(np.array(states))
2) actions = self._model(np.array(states)).numpy()
смысл тот же, результаты не проверял 1в1 но работает, НО второй вариант ощутимо быстрее... кто-то знает почему и, главное, что исп. в, грубо говоря, продакшене?
1) actions = self._model.predict(np.array(states))
2) actions = self._model(np.array(states)).numpy()
смысл тот же, результаты не проверял 1в1 но работает, НО второй вариант ощутимо быстрее... кто-то знает почему и, главное, что исп. в, грубо говоря, продакшене?