



Y
Size: a a a
2019 November 06
E
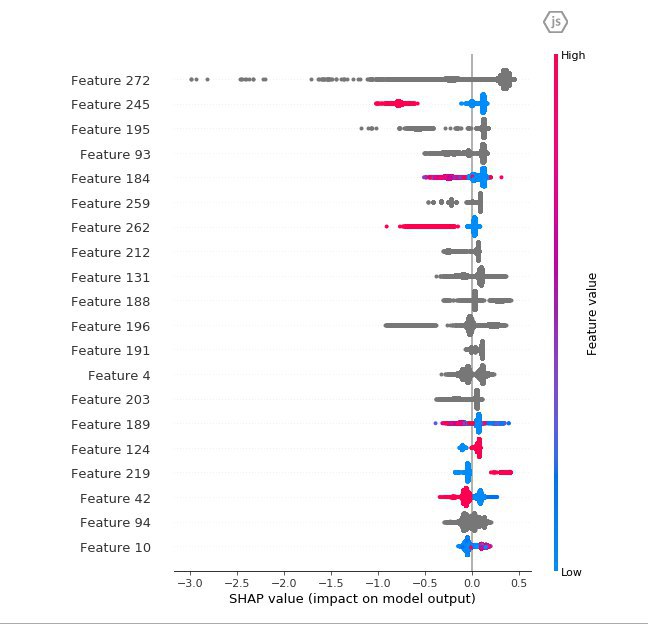
все верно - серое это фичи категориальные
Y
все верно - серое это фичи категориальные
но я в cat_features указывал все столбцы, разве не должно тогда все быть серым?
Y
Или это ещё как-то вычисляется?
E
мы потом смотрим серые категориальные смотрем индивидуально
E
щас
MK
Если категориальные признаки инты, то они раскрашиваются шапом
E
+
Y
И ещё хотел спросить, можно ли как-то получить результат не в виде графика, а в виде таблицы , вроде такого: фича 1 = 28; фича 2 = 42..., => класс 1 ?
Y
Просто, чтобы мне точно сказали, какое значение к какому предсказанию приведёт :)
Y
Или может кто-нибудь объяснить, как интерпретировать эти результаты? Вот у меня есть два класса и 277 фич, как понять, какое значение и какой фичи влияет на результат классификации? :)
DK
Серые точки это баг библиотеки SHAP https://github.com/slundberg/shap/issues/406
AD
Серые точки рисуются для строк и нанов. Если катфичи строковые, то тоже будет серый цвет.
Y
Серые точки рисуются для строк и нанов. Если катфичи строковые, то тоже будет серый цвет.
А насчёт второго вопроса? :)
DK
SHAP показывает насколько изменение конкретного признака влияет на изменение предсказания модели
DK
На графике признаки отсортированы по этой характеристике, то есть самый верхний влияет больше всего, нижний меньше всего
DK
Надо понимать что это анализ модели а не анализ исходного датасета, например, если есть скоррелированные признаки очень важные, то они по важности могли уехать вниз из-за random strength в сплитах
Y
Понял, спасибо большое :)
2019 November 07
IL
Привет. Пытаюсь разобраться как считаются feature importances.
Что здесь имеется в виду под ranking? Logloss - это non-ranking?
Possible values:
FeatureImportance: Equal to PredictionValuesChange for non-ranking metrics and LossFunctionChange for ranking metrics (the value is determined automatically)
Что здесь имеется в виду под ranking? Logloss - это non-ranking?
IL
Вот ranking (для задач ранжирования) метрики: https://catboost.ai/docs/concepts/loss-functions-ranking.html
Остальные, соответственно, не ranking
Остальные, соответственно, не ranking