Часть 2
Движок мой подразумевал то, что я скомпилирую его один раз, а ресурсы конкретной игры будут загружаться при запуске. А значит нужен был какой-то формат описания сцен, переходов, активностей. Выбрал я, конечно же, INI-файл — "искаропки", пишется в любом редакторе, секционность подходит для постраничной игры.
Имя секции соответствовало имени файла (его базовой части) изображения фона — вот вам "convention over configuration"! Первая сцена имела фиксированное имя "begin", соответственно подгружались файлы "begin.bmp" и "begin_m.bmp" — второй, это "маска", то есть тот самый невидимый слой с выделенными цветом объектами.
В секции писалось что-то такое:
При перемещении мыши брался текущий цвет подложки, по нему как по ключу, доставались действие по клику и hint (всплывающая подсказка) для объекта: в примере эти ключ в формате RRGGBB и он же, но с суффиксом "_h" (hint). С текстом всё понятно, а действие "
Ключи секции, имеющие префикс "
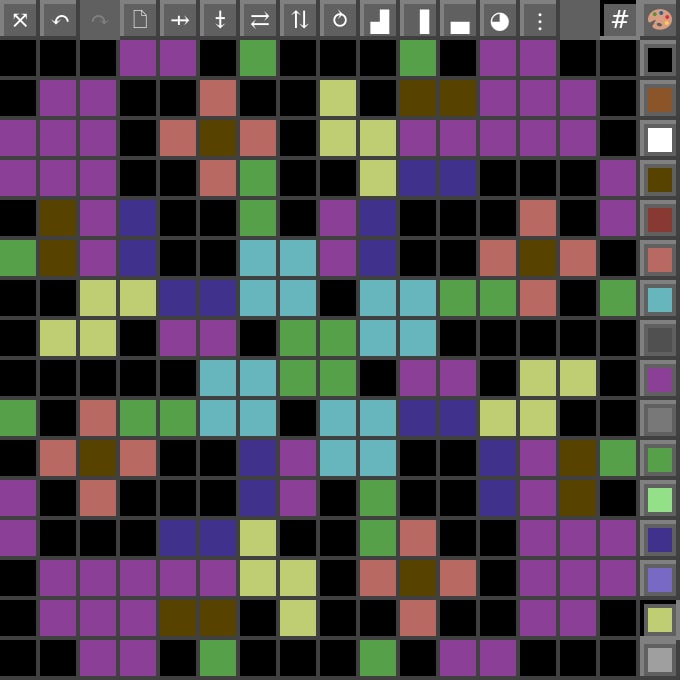
Вот вам спрайт дерева, которое рисовалось поверх пенька на стартовом экране (смотрите предыдущий пост).
Движок мой подразумевал то, что я скомпилирую его один раз, а ресурсы конкретной игры будут загружаться при запуске. А значит нужен был какой-то формат описания сцен, переходов, активностей. Выбрал я, конечно же, INI-файл — "искаропки", пишется в любом редакторе, секционность подходит для постраничной игры.
Имя секции соответствовало имени файла (его базовой части) изображения фона — вот вам "convention over configuration"! Первая сцена имела фиксированное имя "begin", соответственно подгружались файлы "begin.bmp" и "begin_m.bmp" — второй, это "маска", то есть тот самый невидимый слой с выделенными цветом объектами.
В секции писалось что-то такое:
[begin]
00FF00=j{waystone}
00FF00_h=Путевой камень
FF00FF=m{Бедный Ёрик}
FF00FF_h=Череп
FF0000=j{pogost}
FF0000_h=Дорога налево
FFFF00=j{rockwall}
FFFF00_h=Дорога направо
При перемещении мыши брался текущий цвет подложки, по нему как по ключу, доставались действие по клику и hint (всплывающая подсказка) для объекта: в примере эти ключ в формате RRGGBB и он же, но с суффиксом "_h" (hint). С текстом всё понятно, а действие "
j{pogost}" означает "перейти(jump) к секции pogost".Ключи секции, имеющие префикс "
#", описывали "спрайты", то есть накладываемые на подложку объекты. Имя ключа (без префикса) служило именем файла, а значение было числом, которое в формате "640 * y + x" кодировало позицию спрайта относительно верхнего левого угла. Ага, тут я поленился вводить раздельное кодирование координат ;). Если же значение было меньше нуля, то спрайт не рисовался — так можно было показывать и прятать спрайты.Вот вам спрайт дерева, которое рисовалось поверх пенька на стартовом экране (смотрите предыдущий пост).