KT
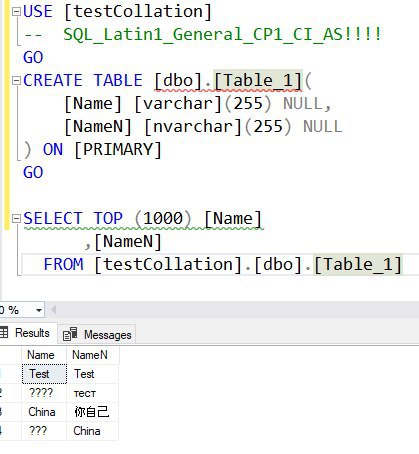
не, я к тому, что если я уже записал строку с кириллицей без всяких N' с полем [customer_city] в БД с коллейшеном SQL_Latin1_General_CP1_CI_AS
я не могу почему-то её прочитать даже указав в SELECT явно другой коллейшен
SELECT
[customer_city] COLLATE Cyrillic_General_CI_AS
Оно там внутри, где неонка, вообще лежит нормально или данные так теряются?
я не могу почему-то её прочитать даже указав в SELECT явно другой коллейшен
SELECT
[customer_city] COLLATE Cyrillic_General_CI_AS
Оно там внутри, где неонка, вообще лежит нормально или данные так теряются?
Create table сбросьте и через профайлер (по хорошему xe) отловите какой insert в базу прилетает