



i
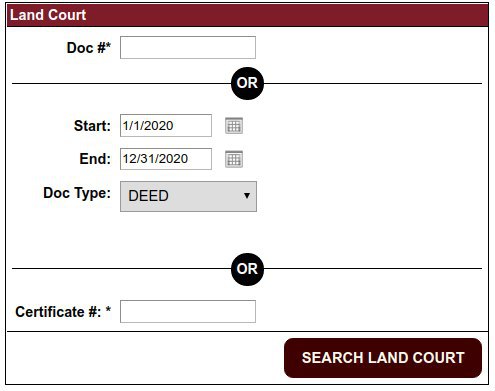
http://www.tauntondeeds.com/Searches/ImageSearch.aspxно после клика на Search Land Court ссылка остается неизменной. Там как то через ajax запрос подгружаются данные.
Так вот, мне нужно использовать selenium чтоб заполнить поля или есть другой способ получения данных?
