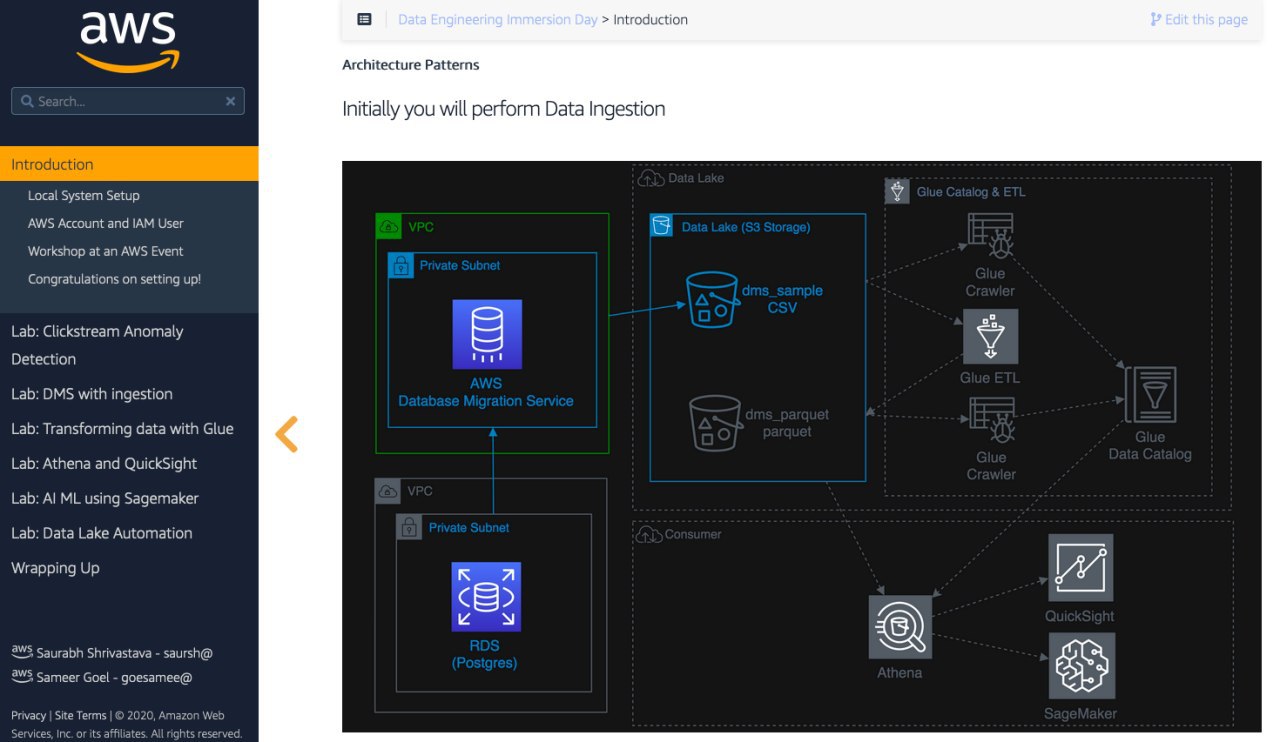
Статья описывает 3 возможных сценария для Spark на AWS.
1) Запустить EMR (Hadoop) и включить в нем Spark. Я такое делал. EMR использует EC2 (виртуальные машины) для вычислений и Spark для логики. Данные можно все хранить на S3, Hadoop FS не используется.
2) Использовать Glue (это такой AWS ETL, который внутри имеет Spark, можно двигать данные и трансформировать. Минимум интерфейса). ДЛя него не нужны виртуальные машины, потому что это serverless (SaaS) решение.
3) Использовать контейнеры на AWS Fargate. Это я не пробовал.
На Азуре будет:
1) HDInsight+Spark или лучше использовать DataBricks
2) Azure Data Factory (но там уже нужно использовать HDInsight или Databricks в качестве вычислений.)
3) Контейнеры на Azure.
Также и на Google Cloud. Я не знаю названий сервисов.
Когда такие возможности появятся у яндекс облака и mail облака, тогда можно уже строить решения на отечественном облаке.
====
Как вы полняли, один из ключевых навыков, это понимать назначение инструмента. Аналитическое решение это как конструктор из блоков. Нужно представлять архитектуру и правильно выбирать компоненты. Именно поэтому на datalearn мы рисовали смешные архитектуры в модуле 1 и потом будем усложнять их. Очень важно понимать, какое решение, для какой ситуации. А как кодить на spark или писать SQL/Python уже можно в процессе работы подтянуть. Но вы должны понимать, когда и почему Spark, а когда это "по воробьям из пушки".
Мы рассмотрим эти варианты 1 и 2 на datalearn.