Всем привет. Думаю, предыдущую рубрику можно закрывать. Я постарался охватить все основные направления работы с данными и дать пошаговый план развития с полезными ссылками для каждой позиции.
Теперь я хочу начать следующую рубрику, которая будет посвящена архитектуре аналитических решений. Думаю, что более эффективно изучать материал, двигаясь от общего к частному, от абстракции к конкретике. Такой подход позволяет наиболее быстро и эффективно разобраться в любом предмете. Поэтому, я предлагаю сначала взглянуть на архитектуру решений в целом, а затем подробно разобрать каждый из её элементов.
Сегодня я хочу коснуться базовых вещей - концепций, на которых строится любая аналитическая архитектура. В последующих постах для закрепления я буду брать примеры реальных решений и разбирать их, рассказывая какие инструменты за какую задачу отвечают.
Итак, поговорим о концепциях.
Если абстрагироваться, то любую аналитическую архитектуру можно разделить на 5 слоев:
1) Source Layer (слой источников данных);
2) Data Processing Layer (слой обработки данных);
3) Storage Layer (слой хранения данных);
4) Access Layer (слой доступа к данным);
5) Service Layer (сервисный слой).
Разберём каждый слой подробнее:
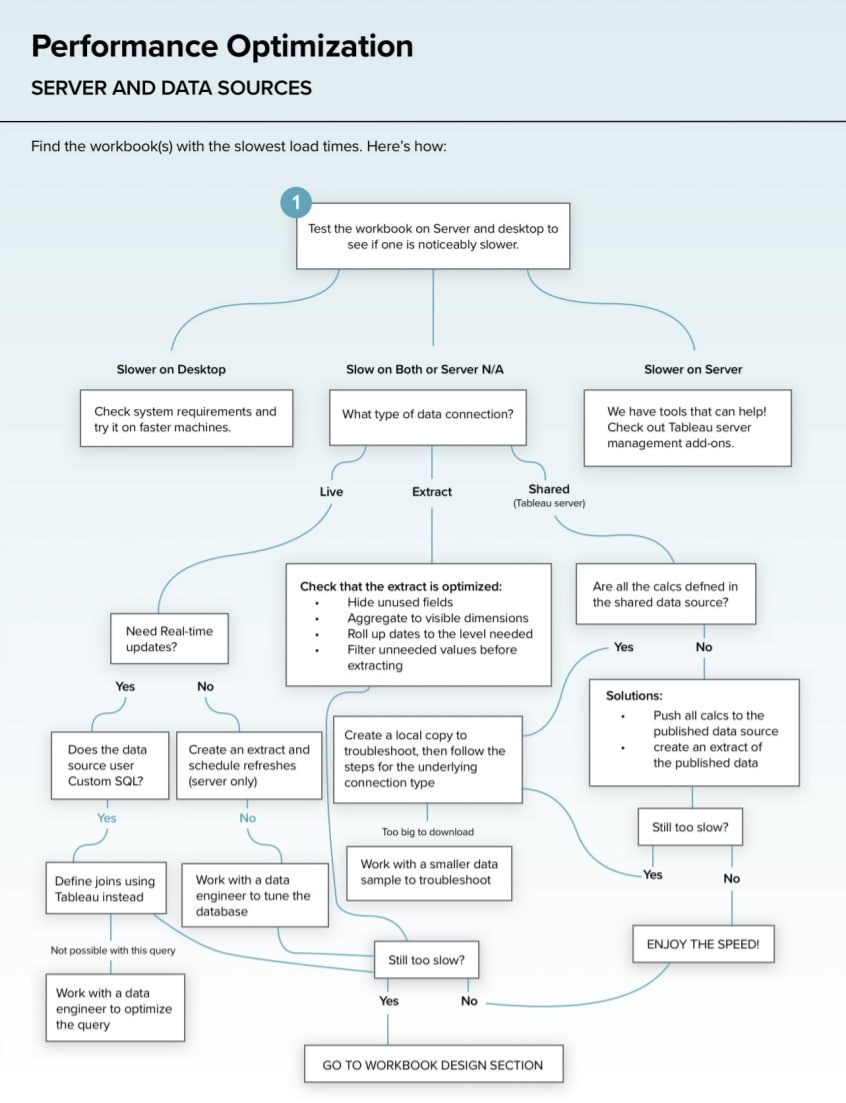
Source Layer. Этот слой отвечает за все наши источники данных. Это могут быть OLTP базы данных, которые отвечают за обслуживание операционной деятельности компании, различные файлы, в которых хранятся операционные данные (файлы могут быть различных форматов: csv, xlsx, txt, json, xml и т.д.), API внешних систем, IoT (интернет вещей) и др.
Примеры сервисов и инструментов на этом уровне: MySQL СУБД, Google Analytics, Facebook Ads, FTP/SFTP сервер, Salesforce, Kafka.
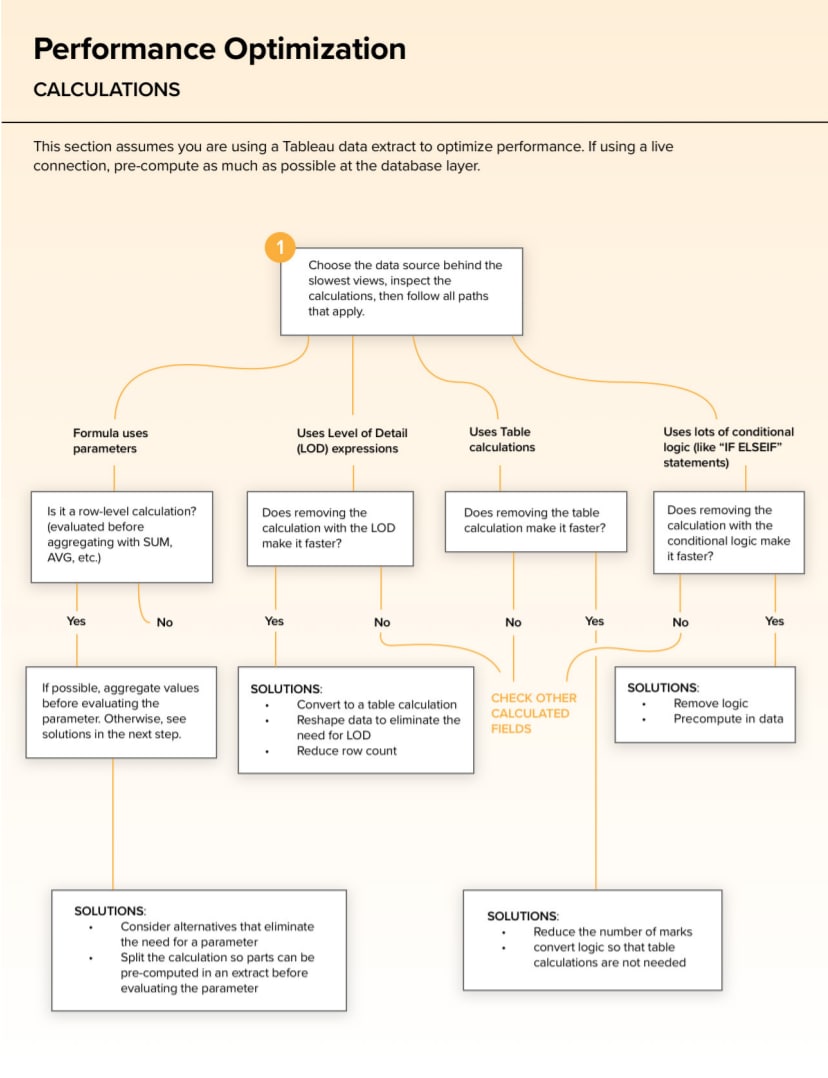
Data Processing Layer. Этот слой отвечает за обработку данных. Как раз здесь встречаются такие понятия, как ETL/ELT и data pipelines. Т.е., благодаря этому слою, осуществляется извлечение данных из источников, трансформация данных, движение данных и загрузка их в централизованный слой хранения данных.
Примеры сервисов и инструментов на этом уровне: Python и SQL, Apache Airflow, dbt, Pentaho Data Integration, Matillion ETL, Spark, AWS Glue, Azure Data Factory и др.
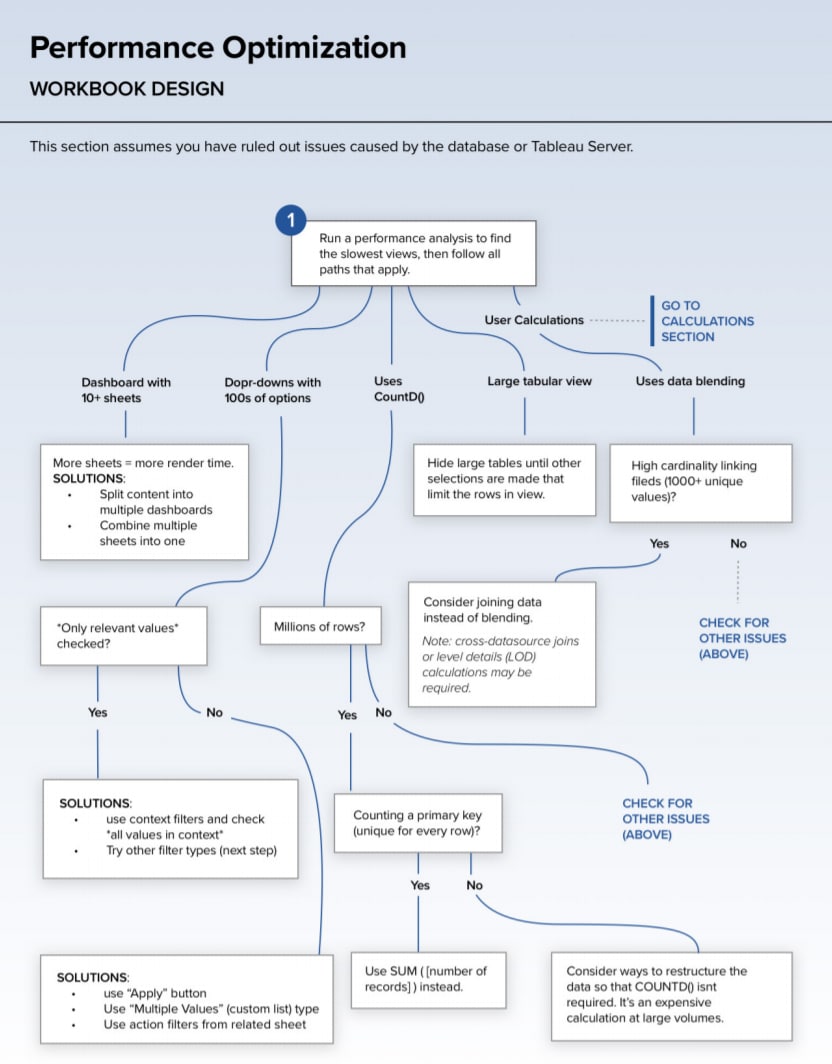
Storage Layer. Этот слой отвечает за централизованное хранение данных. Здесь появляются такие понятия как Data Warehouse (DWH), Data Lake и новомодное слово Lakehouse. Какое решение использует компания зависит от её задач. Например, если компании аналитическое решение нужно для конечной визуализации данных в BI-инструменте и для написания SQL-запросов к обработанным данным для поиска инсайтов, то достаточно будет использовать хранилище данных. Если у компании есть Data Science департамент, который строит ML-модели на основе данных для задач бизнеса, то разумным решением будет также использование Data Lake или Lakehouse, так как построение моделей требует обработки большого количества данных и для таких целей используется более сложный non-SQL код; Data Lake в таком случае является более гибким решением, так как обеспечивает быстрый прямой доступ к файлам.
Большим компаниям обычно нужен микс хранилища данных и озера данных, т.е., так называемая, Data Platform. Платформа данных как раз заточена на то, чтобы обслуживать и уровень BI-приложений и Data Science.
Примеры сервисов и инструментов на этом уровне: AWS S3, Azure Data Lake, Google Cloud Storage, AWS Redshift, Azure Synapse, Google BigQuery, HDFS (Hadoop), Vertica, Clickhouse и др.
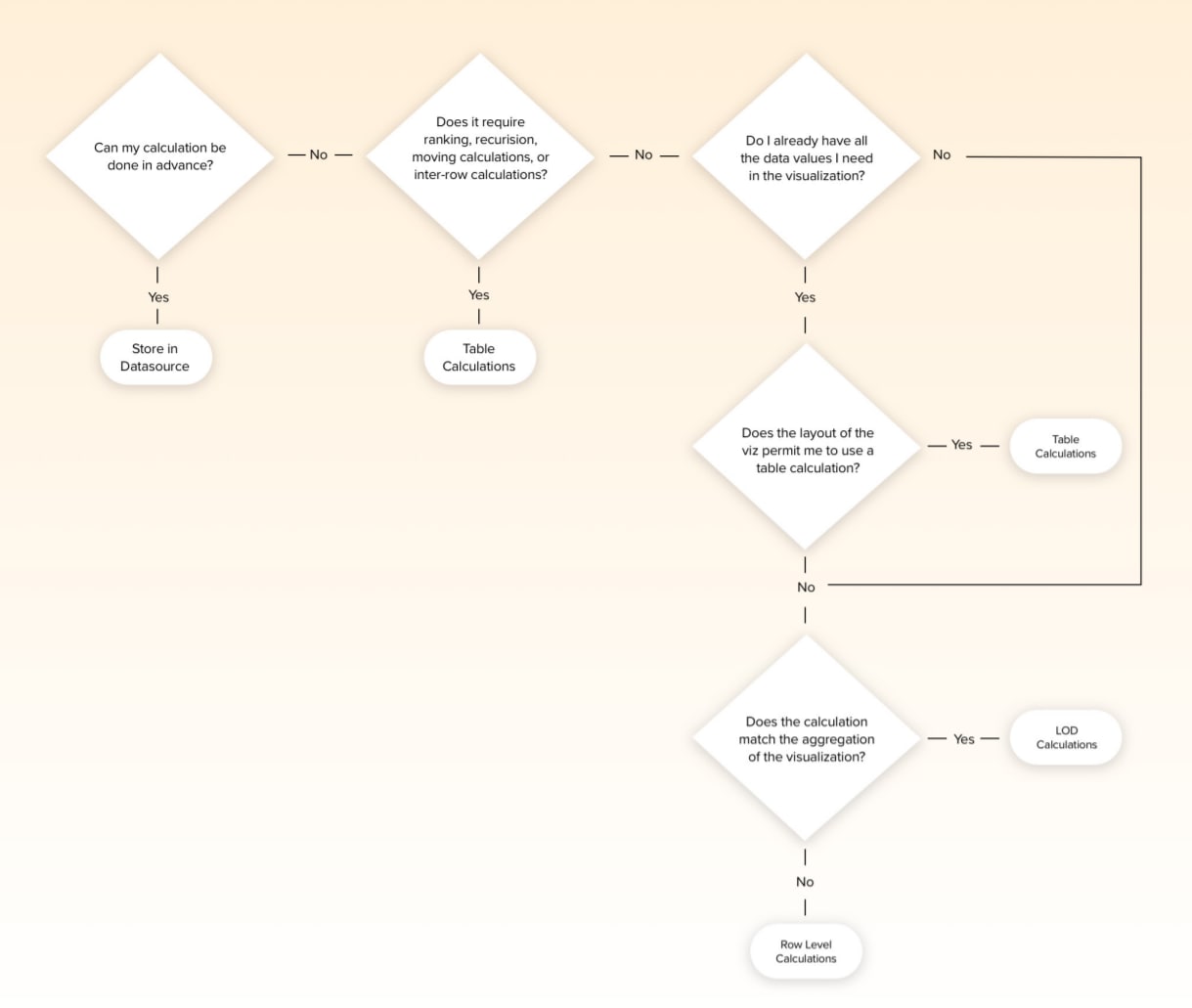
Access Layer. Слой доступа к данным. Здесь в игру вступают BI-приложения, data-аналитики и data-сайнтисты, которые используют данные (уже находящиеся в Data Lake или DWH) для своих целей. В качестве приёмщика данных может также выступать база данных, которая обслуживает back-end интернет-магазина и позволяет показывать рекомендуемые товары на основе ML-моделей. В общем, этот слой является верхушкой айсберга, ради которой собственно и затевается построение всей системы.
Примеры сервисов и инструментов на этом уровне: Power BI, Tableau, AWS SageMaker, GCP AI Platform и др.