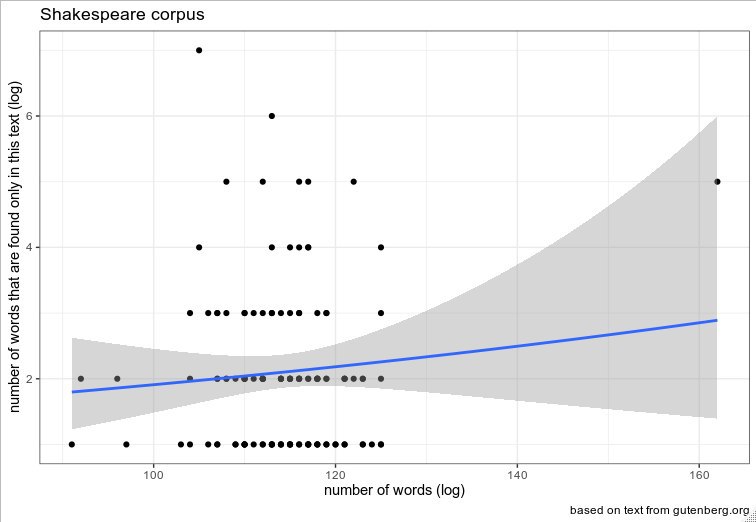
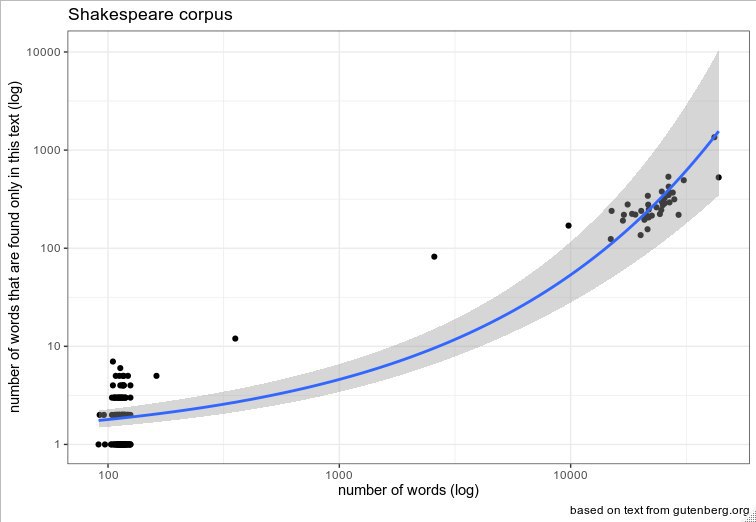
Да, в соседнем чате тоже предложили две модели. Минус метода двух моделей, или введения переменной большие-маленькие тексты заключается в том, что мы можем потенциально найти рукопись Шекспира, которая будет посередине, например, 2500 слов.
В соседнем чате предложили в таком случае классифицировать новую находку, а дальше уже пихать в модель. Я не в восторге от этой идеи, но право на существование она, конечно, имеет.
Другое предлоежние: нарезать большие тексты на маленькие.
Или можно сразу сделать иерархическую модель на основе предположения, что есть два основных типа текстов, но ещё и вместе их учитывать. И тогда в теории эта модель должна быть устойчива к появлению "серединных" текстов.