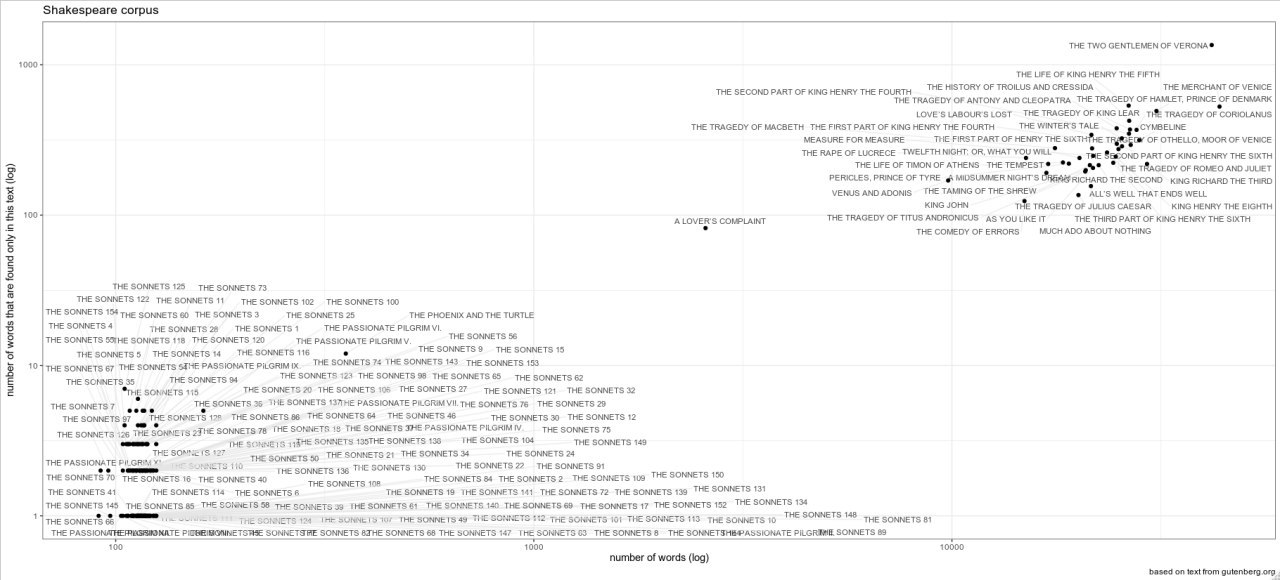
Дорогие, я захотел смоделировать количество слов, которые встретились только в одном тексте из корпуса Шекспира. Получился вот такой график. Я хочу научиться предсказывать количество уникальных слов на основании длины текста. Как видно на рисунке, получаются два кластера: с всякими мелкими тексатми, и с всякими крупными текстами, а между ними дыра, так что регрессия, которая бы смотрела на все это вместе, наверное, бессмысленна. Что бы вы предложили? Я придумал искусствено разделить на эти кластеры и использовать их в качестве предиктора, однако мне это решение не совсем нравится. Можно выкинуть маленькие тексты (они составляют 2% всего корпуса), но тогда модель их эффект вообще не учтет.
Проблема взята из раздела 6.2 "Computer Age Statistical Inference"