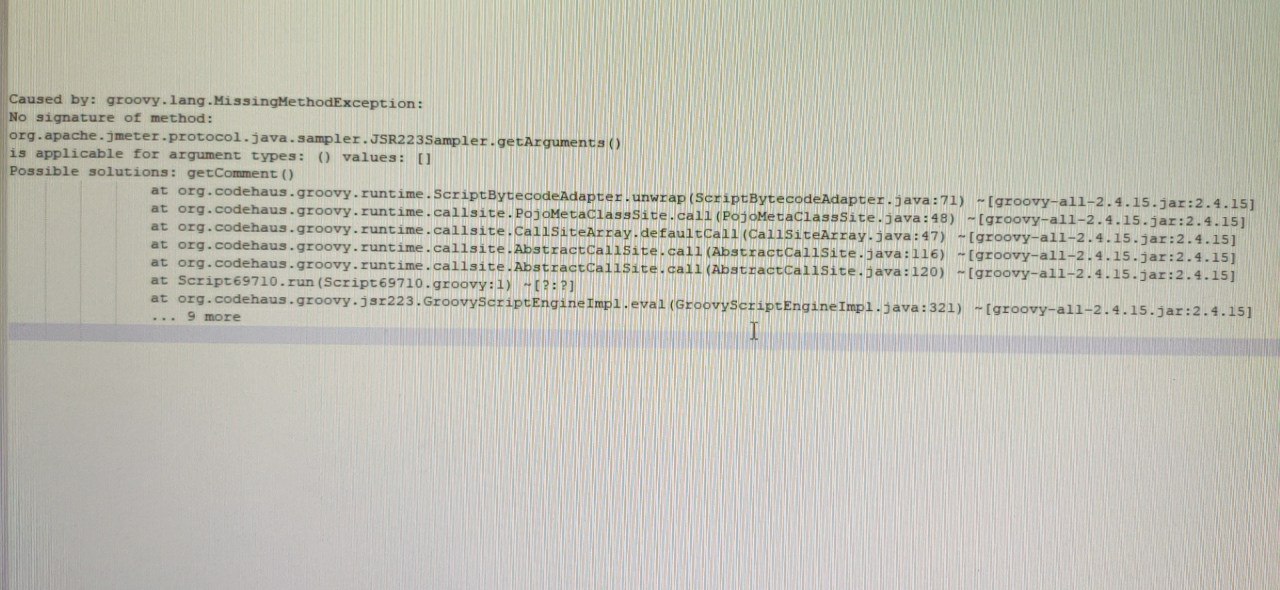
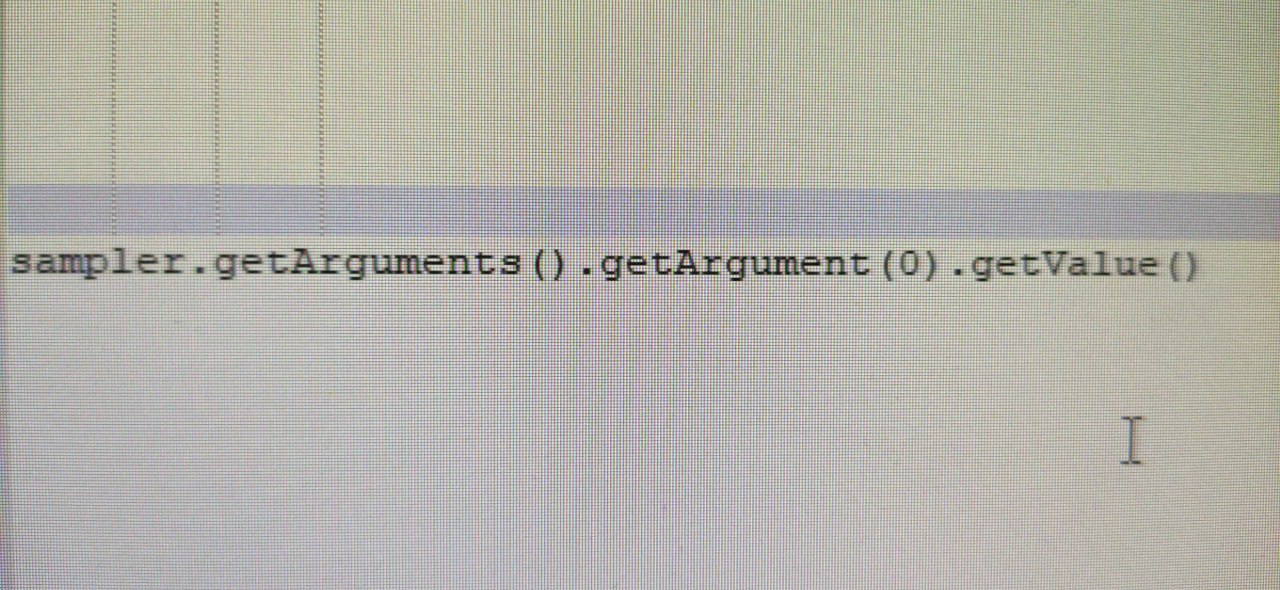
ВС
@smirnovqa если в курсе, есть ли софтовое ограничение на на виртуальных пользователей в JMeter? Видел где то статейку, i5+8gb дали примерно 9000 авктивных. Но я хочу запускать через агенты тимсити, там то железяки помощнее. Максимум во что могу упереться это количество активных подключений сети. Так вот и интересно на сколько я смогу разогнать один воркер?
Это извечный вопрос. Одним словом не ответить. В целом - есть ограничение.
На станции с 4 Гбайт ОЗУ делали раньше всегда 1000 потоков. Было у нас такое правило. Сильно не думали.
Потом подумав стал мониторить, сколько потоков создано и сколько памяти выделено.
И поделив одно на другое можно определить стоимость одного вашего потока. Она зависит от вашего сценария, постпроцессов. Примерно 10 КБайт и больше (с постпроцесорами, скачиванием больших ответов, ...). 8 000 000 / 10 = 800 000. Но зная точный размер памяти под поток можно определить сколько потоков можно уместить в 8 Гбайт для вашего скрипта.
Сделайте так. Запустите тест. Откройте jvisualvm. Откройте там jmeter. Сделайте полную сборку мусора, и сразу heap dump. Грубо поделив размер кучи на потоки получим средний размер. А если точно, то... Откройте heapdump в Memory Analyser (mat). Вверху в панели будет кнопка статистики потокам. Посмотрите сколько памяти в чистую заняли потоки. И точно поделите этот размер на их количество.
Много подключений создать тоже непросто. Надо станцию настраивать. Увеличить лимиты на диапазон исходящих соединений (диапазон портов), включить переиспользование сокетов, увеличить количество дескрипторов на процесс (по умолчанию 4096), ...
Тут необходимость большого количества пользователей приводит к вопросу ускорения работы сценария. Нужен же TPS, а не пользователи. Чем меньше тормозит сценарий, тем эффективнее используются потоки. Тем меньше их нужно.
И начать стоит с подбора таймера. Чем меньше поток спит в таймере, тем лучше он работает. Throughput Shaping Timer хорош. Другие таймеры тоже хороши. Их под задачу подбираете.
Ещё некоторые советы собрал в докладе Ускоряем Apache JMeter.
На станции с 4 Гбайт ОЗУ делали раньше всегда 1000 потоков. Было у нас такое правило. Сильно не думали.
Потом подумав стал мониторить, сколько потоков создано и сколько памяти выделено.
И поделив одно на другое можно определить стоимость одного вашего потока. Она зависит от вашего сценария, постпроцессов. Примерно 10 КБайт и больше (с постпроцесорами, скачиванием больших ответов, ...). 8 000 000 / 10 = 800 000. Но зная точный размер памяти под поток можно определить сколько потоков можно уместить в 8 Гбайт для вашего скрипта.
Сделайте так. Запустите тест. Откройте jvisualvm. Откройте там jmeter. Сделайте полную сборку мусора, и сразу heap dump. Грубо поделив размер кучи на потоки получим средний размер. А если точно, то... Откройте heapdump в Memory Analyser (mat). Вверху в панели будет кнопка статистики потокам. Посмотрите сколько памяти в чистую заняли потоки. И точно поделите этот размер на их количество.
Много подключений создать тоже непросто. Надо станцию настраивать. Увеличить лимиты на диапазон исходящих соединений (диапазон портов), включить переиспользование сокетов, увеличить количество дескрипторов на процесс (по умолчанию 4096), ...
Тут необходимость большого количества пользователей приводит к вопросу ускорения работы сценария. Нужен же TPS, а не пользователи. Чем меньше тормозит сценарий, тем эффективнее используются потоки. Тем меньше их нужно.
И начать стоит с подбора таймера. Чем меньше поток спит в таймере, тем лучше он работает. Throughput Shaping Timer хорош. Другие таймеры тоже хороши. Их под задачу подбираете.
Ещё некоторые советы собрал в докладе Ускоряем Apache JMeter.