Если у тебя ОП не хватит чтобы держать даже все строки без повторов то тут алгоритм в заключается в том чтобы открыть поток, считать первую строку, записать её в второй поток, далее вторую строку читаешь, пробегаешься по предыдущим строкам в потоке записывая их во временную переменную, если нет копий, записываешь и т д
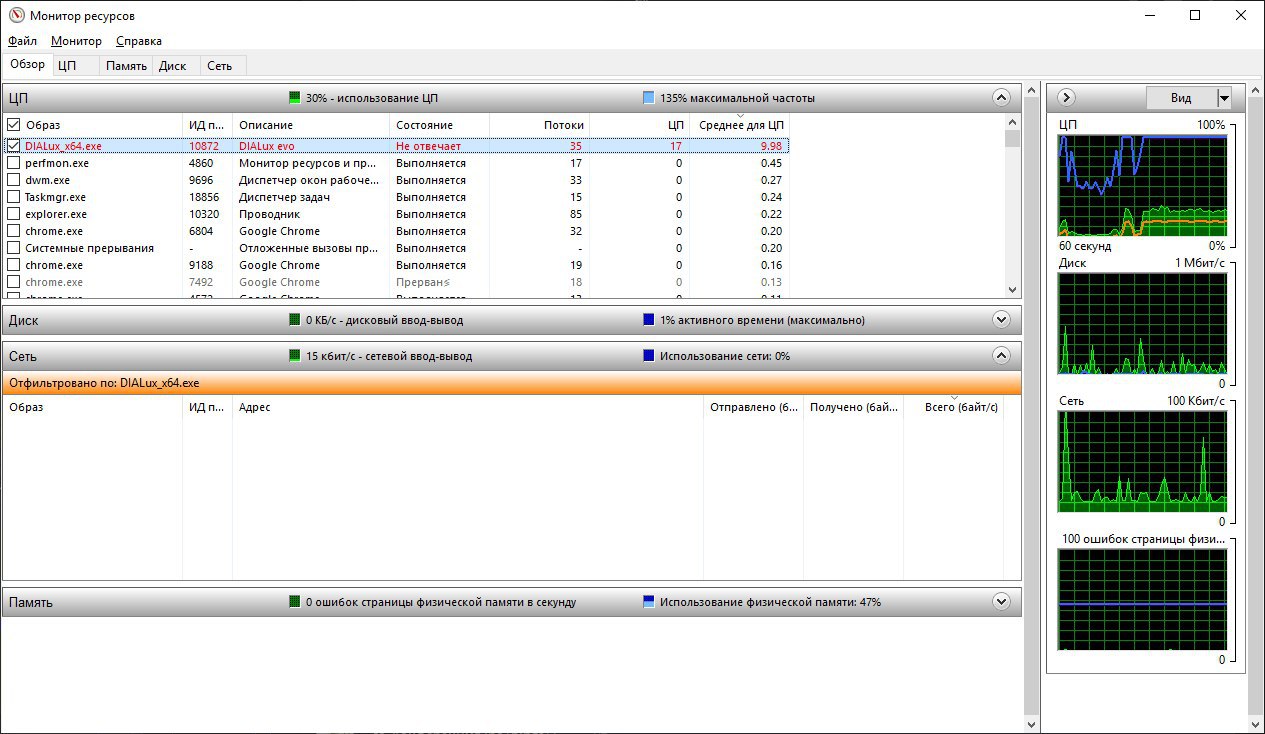
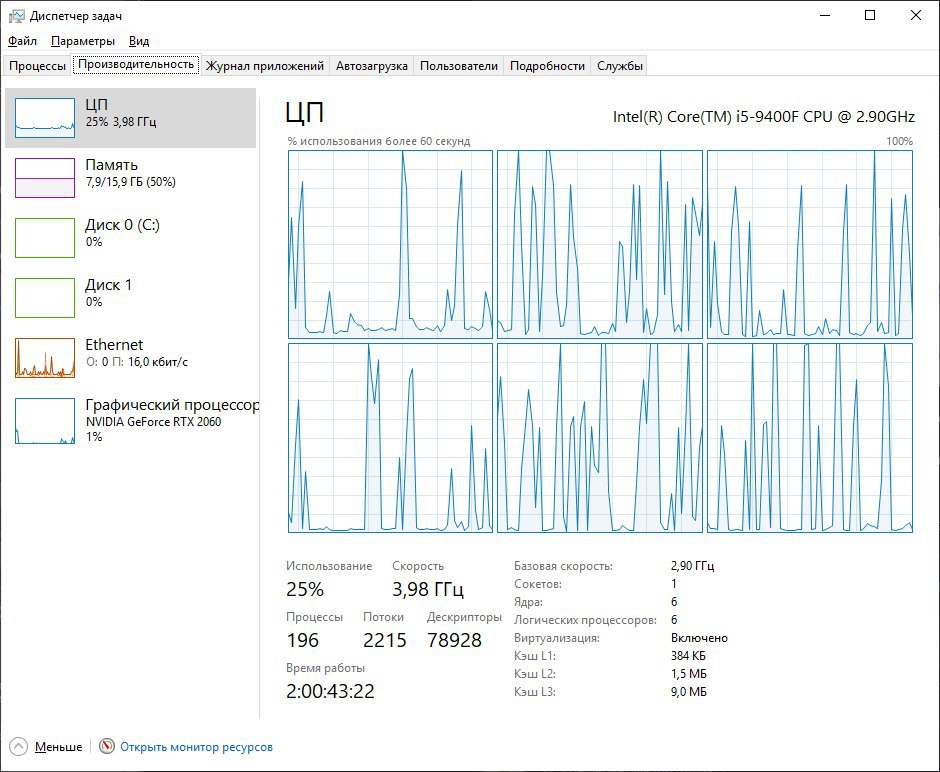
да, я тоже примерно так думал сделать, спасибо) но проще наверное будет не изобретать велосипед, и уменьшить размер файла, в котором искать повторы надо, чтобы поместился в оперативку))