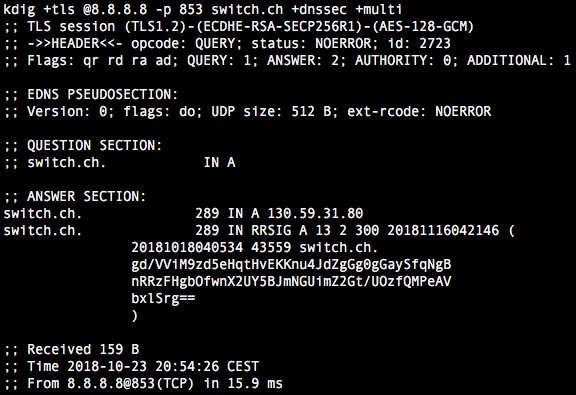
IPv6 адресов много, очень много, поэтому некоторые виды техник исследований IPv6 которые доступны в IPv4, например, перебор становятся недоступны (на текущем этапе). Но тут на передний план выходят настоящие математики, которые знают теорию вероятности и статистику, и то что для админа много здесь всего лишь цифра.
Поэтому адреса были собраны, препарированы и сформированы в отчёте на сайте http://entropy-ip.com. Адреса обезличены в старшей части - все префиксы
Простой отчёт не содержит никаких уравнений и читается легче:
1. Сначала посчитали энтропию (чем больше число, тем больший разброс значений в этом месте IPv6 адреса) - это синяя линия на первом графике. Так как статья академическая то сравнили ещё со значением ACR из другой академической статьи (на него можно внимания не обращать).
2. На основе значений энтропии выделили несколько сегментов в IPv6 адресе, по тому как сильно отличаются они друг от друга. В этих сегментах (один или несколько октетов), посчитали статистику появления того или иного значения. Если задан диапазон значений (зелёный курсив со звёздочкой), то из него уже исключены все ранее приведённые значения. Например, вероятность что в 16 октете будет число 3 - 9,5%, а что будет какое либо другое число кроме 3,5,4,8 - 67,52%
3. Дальше построили Байесову сеть - зависимость появления какого либо числа в каком-то месте, от того какое число стоит в другом месте. И сделали интерактивную табличку, в которой можно выбрать число и увидеть как изменится вероятность (отличается цветом) появление других чисел в адресе. Такие же таблички приведены на первой странице http://entropy-ip.com для разных наборов данных (ссылки
В самом конце были сгенерированы адреса, которые с большой вероятностью могут встретится в сети и быть активными. Попадание при используемом методе 40% и вот это уже очень много - перебирать ничего не нужно даже если активна всего половина адресов из предполагаемых то это в бесконечное количество раз лучше чем проверить даже 2^64.
Конечно остаётся вопрос получения исходных данных по которым можно проводить анализ. Но это не такой сложный вопрос, особенно если иметь определённую цель. Тем более что инструментарий доступен на GitHub Akamai, а метод расписан от и до.
Поэтому адреса были собраны, препарированы и сформированы в отчёте на сайте http://entropy-ip.com. Адреса обезличены в старшей части - все префиксы
2001:db8::/32. По факту в простом отчёте префикс всегда 2001:db8:0000::/40 и 14 октет всегда 0, возможно это издержки набора данных (тем более что некоторые границы видно и в других местах). Но так как в полный отчёт я погрузился не до конца не могу по этому поводу ничего сказать. Его можно читать, если вы давно не видели формул придётся кое-что вспомнить. Там сильно разжёвано по существу, но некоторые отсылки придётся вспоминать или пропускатьПростой отчёт не содержит никаких уравнений и читается легче:
1. Сначала посчитали энтропию (чем больше число, тем больший разброс значений в этом месте IPv6 адреса) - это синяя линия на первом графике. Так как статья академическая то сравнили ещё со значением ACR из другой академической статьи (на него можно внимания не обращать).
2. На основе значений энтропии выделили несколько сегментов в IPv6 адресе, по тому как сильно отличаются они друг от друга. В этих сегментах (один или несколько октетов), посчитали статистику появления того или иного значения. Если задан диапазон значений (зелёный курсив со звёздочкой), то из него уже исключены все ранее приведённые значения. Например, вероятность что в 16 октете будет число 3 - 9,5%, а что будет какое либо другое число кроме 3,5,4,8 - 67,52%
3. Дальше построили Байесову сеть - зависимость появления какого либо числа в каком-то месте, от того какое число стоит в другом месте. И сделали интерактивную табличку, в которой можно выбрать число и увидеть как изменится вероятность (отличается цветом) появление других чисел в адресе. Такие же таблички приведены на первой странице http://entropy-ip.com для разных наборов данных (ссылки
Dataset).В самом конце были сгенерированы адреса, которые с большой вероятностью могут встретится в сети и быть активными. Попадание при используемом методе 40% и вот это уже очень много - перебирать ничего не нужно даже если активна всего половина адресов из предполагаемых то это в бесконечное количество раз лучше чем проверить даже 2^64.
Конечно остаётся вопрос получения исходных данных по которым можно проводить анализ. Но это не такой сложный вопрос, особенно если иметь определённую цель. Тем более что инструментарий доступен на GitHub Akamai, а метод расписан от и до.