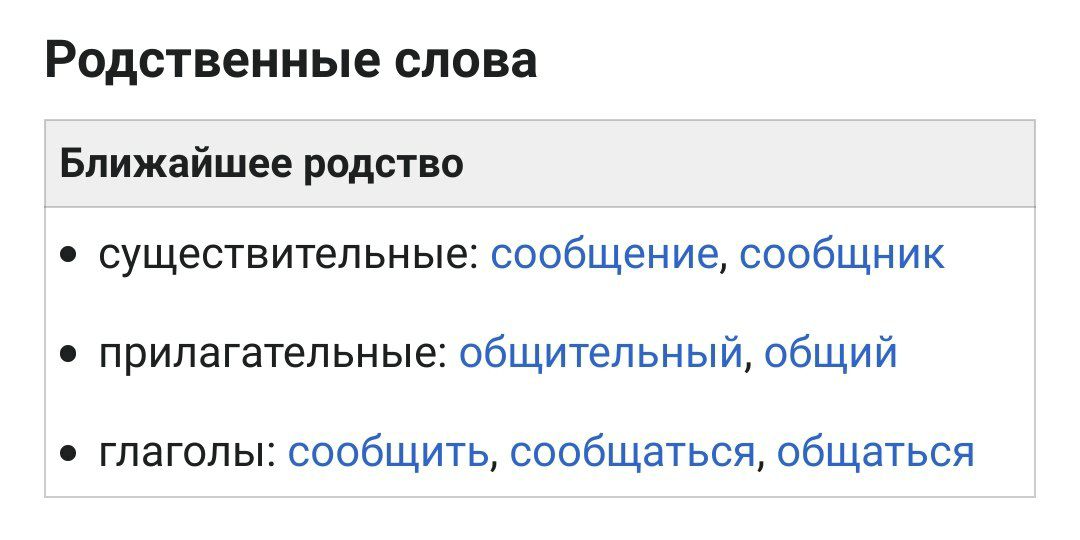
В Pullenti зашит так называемый словарь дериватных групп (их там около 15000), где группа - это набор однокоренных слов разных частей речи (ПРОИЗВОДСТВО ПРОИЗВОДИТЕЛЬ ПРОИЗВОДСТВЕННЫЙ ПРОИЗВОДИТЬ ПРОИЗВЕСТИ ПРОИЗВЕДЕННЫЙ и т.д.). То есть для словоформы можно получить группу, брать из неё первое же слово (обычно существительное), которое и будет "сильной нормализацией". Использование: в классе Pullenti.Semantic.Utils.DerivateService функция FindDerivates - вернёт список групп (т.к. словоформа может входить в несколько групп, но обычно в одну) или null, если не найдено в словаре. Для неизвестных слов может генерировать группы, похожие на существующие.