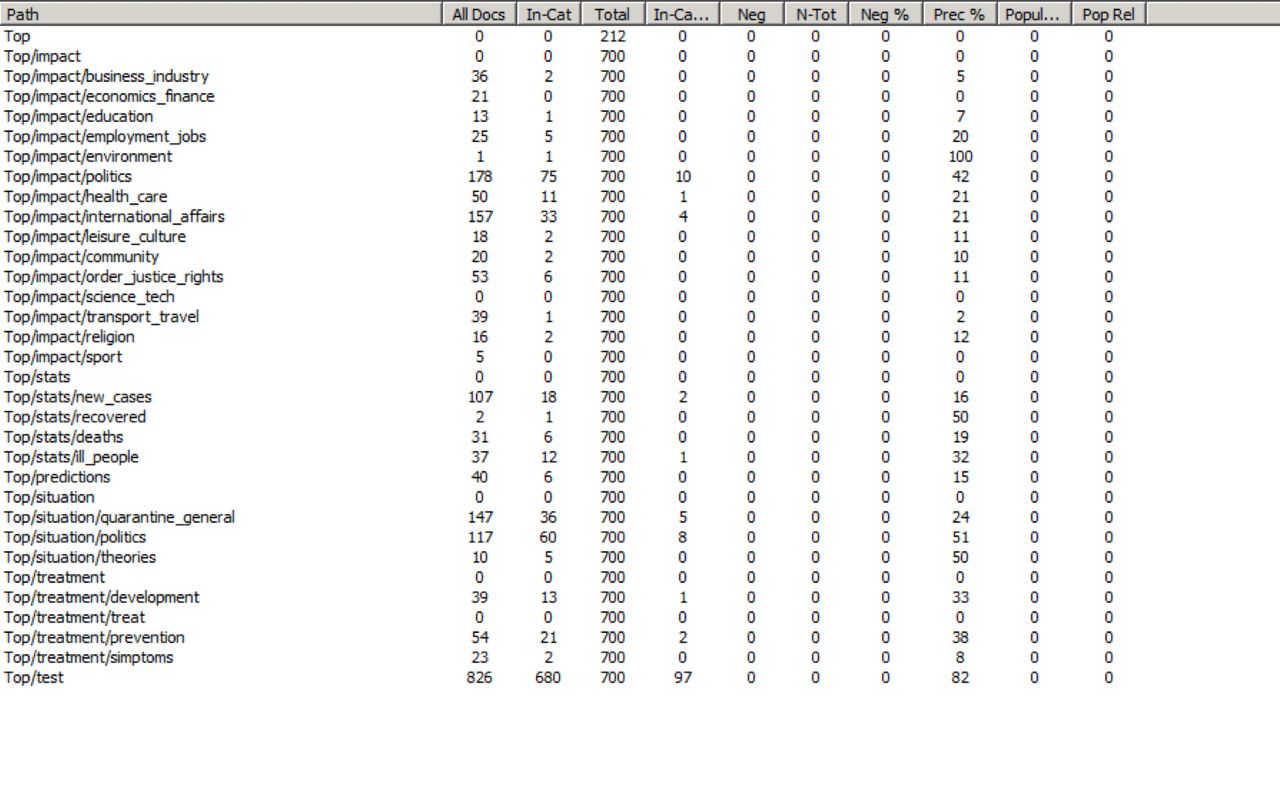
VS
Size: a a a
2021 April 16

M
Никто не знает, есть ли какой нибудь датасет, который перефразирует к существительным. Например "where is" в "location"? В особенности интересует немецкий
VS
устанавливаю tensorflow-text = 2.1 и запускаю
CN
Можете подсказать, есть ли датасет с такими характеристиками: у нас есть текстовые данные и таргет к ним, на этом всем решается задача классификации (не важно сколько классов). На этих же текстовых данных есть выделенные слова, которые больше всего «влияют» на таргет (условно, 5 или 10 слов). То есть для каждого текста и класса есть свой набор из 5-10 слов
VV
рус или англ?
CN
без разницы
VV
насколько пересекающиеся топики нужны?
VV
уровня политика, спорт, шоу-бизнес или уровня кредиты депозиты И так далее узкогго сектора
CN
например, отзывы покупателей в каком-нибудь интернет магазине или что-то близкое, но если такого нет подойдет любой из вышеперечисленных
VV
ну... вопрос классификация или сентимент анализ?
VV
какая конечная цель?
VV
хотите классификатор product+features сначала?
FV
Я так понимаю, что подойдет SemEval-2014 Task 4
FV
https://alt.qcri.org/semeval2014/task4/ вроде тут должен быть
VV
я так понимаю, еще и таксономия классов должна быть, а в ней для каждого класса ключи
ДС
Как я понимаю, что-то в духе поиска keyword, но с известным GT.
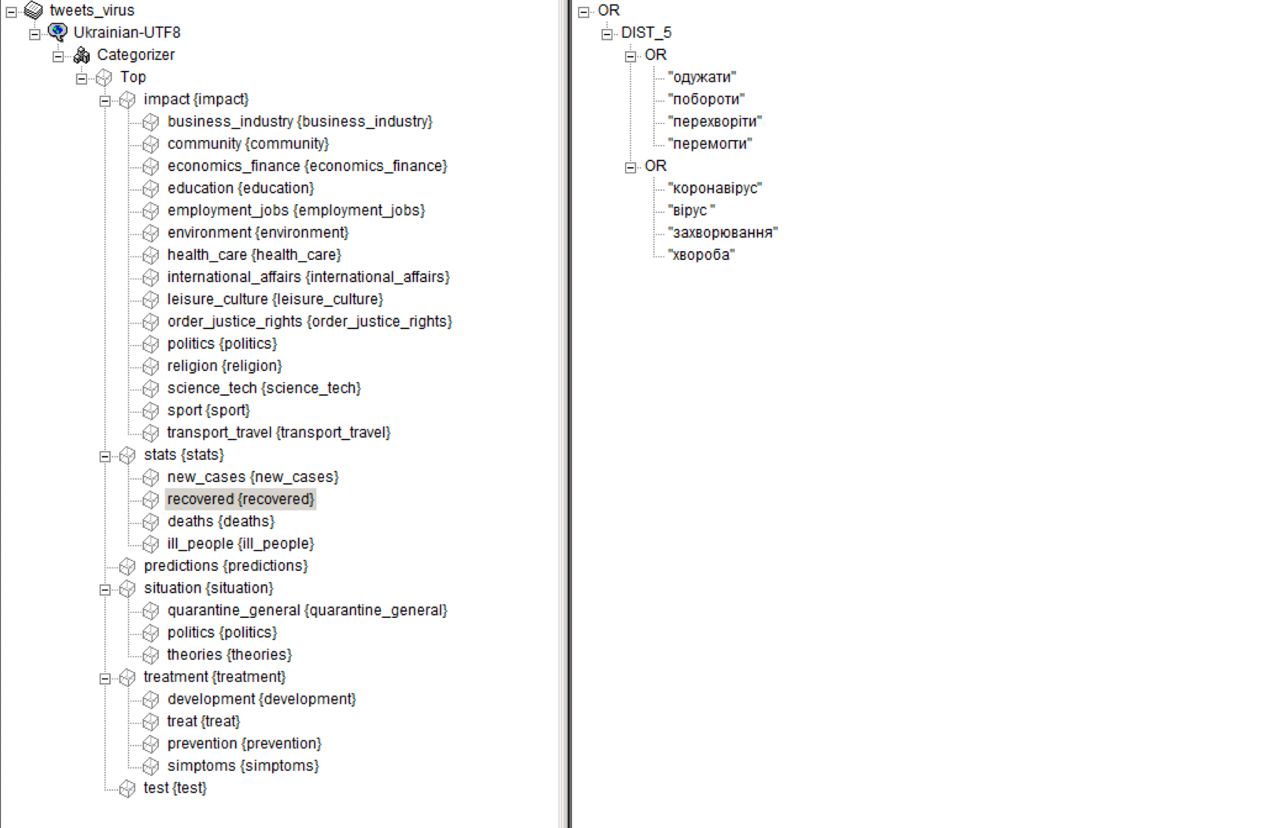
VV
скорее всего такое, не поиска, а дефиниции ключей
VV
а потом еще и результаты классификации