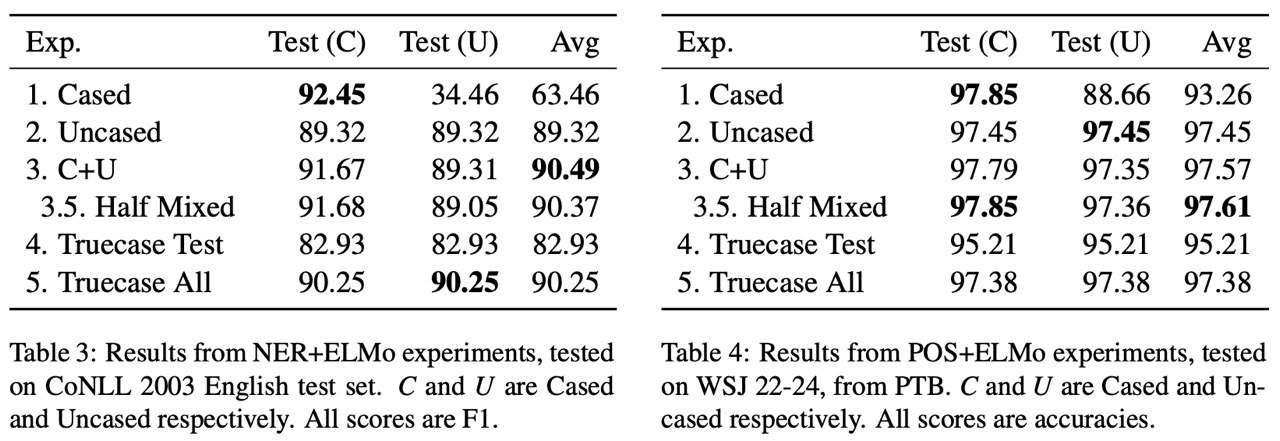
смотрите. 92.45 -> 90.25 (учить на truecase) примерно соответствует 92.45 -> 89.32 (учить на lowercase)
и там и там происходит потеря качества, т.е. предсказание кейса не помогает. хм, ну ок, чуть-чуть помогает, оказывается. на NER.
а на POS эти ±0.2% неразличимы.
ну и лучший (и достаточный) вариант обучения, получается, cased+uncased.