Почему Natasha не использует Transformers. BERT в 100 строк.
По мотивам треда с
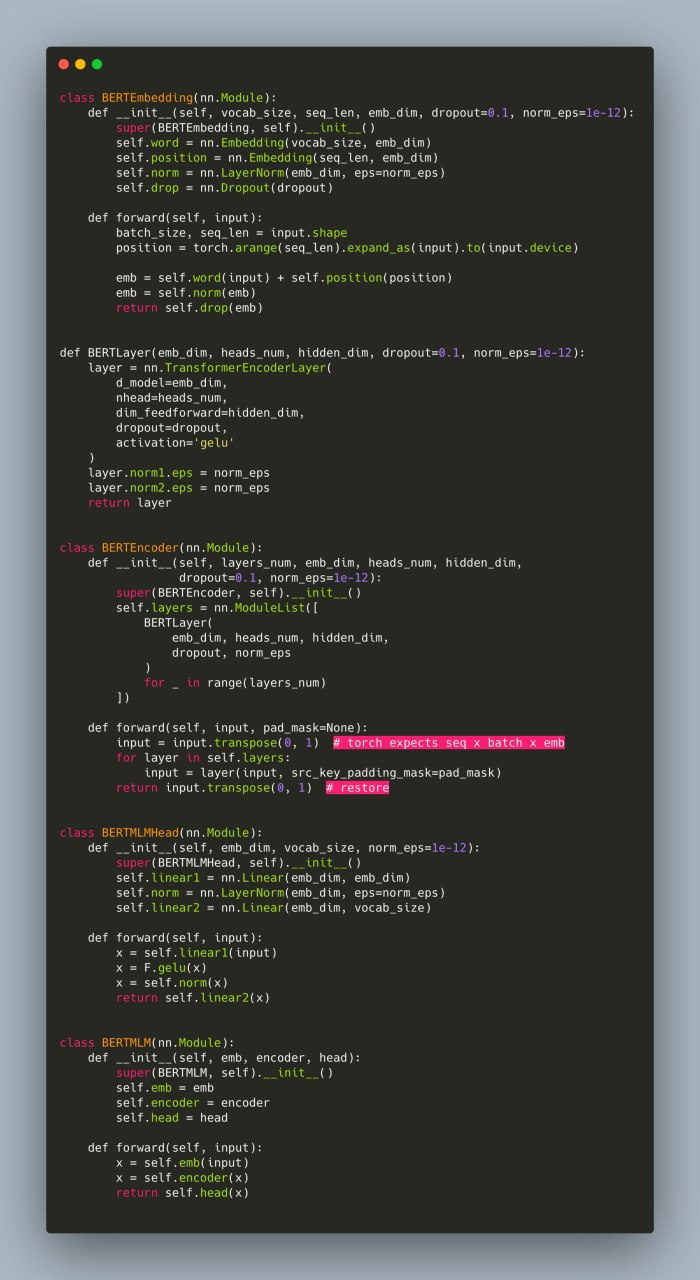
@mtikhomi https://t.me/natural_language_processing/17253Сейчас, для обучения моделей с BERT-like архитектурой, принято использовать Transformers от Hugging Face. Transformers — это 100 000 строк кода на Python. Желаю удачи, разобраться, что пошло не так, когда взорвётся loss или на инференсе будет мусор. Ладно, там много кода дублируется. Пускай мы тренируем RoBERTa, довольно быстро локализуем проблему до ~3000 строк кода, но это тоже немало. С современным PyTorch, мне кажется, библиотека Transformers не так актуальна. С torch.nn.TransformerEncoderLayer код RoBERTa-like модели занимает 100 строк: