EV
Приходится использовать томиту, потому что необходимы отношения между сущностями.
Size: a a a
EV
DV
DV
DV
EV
MC
DV
DV
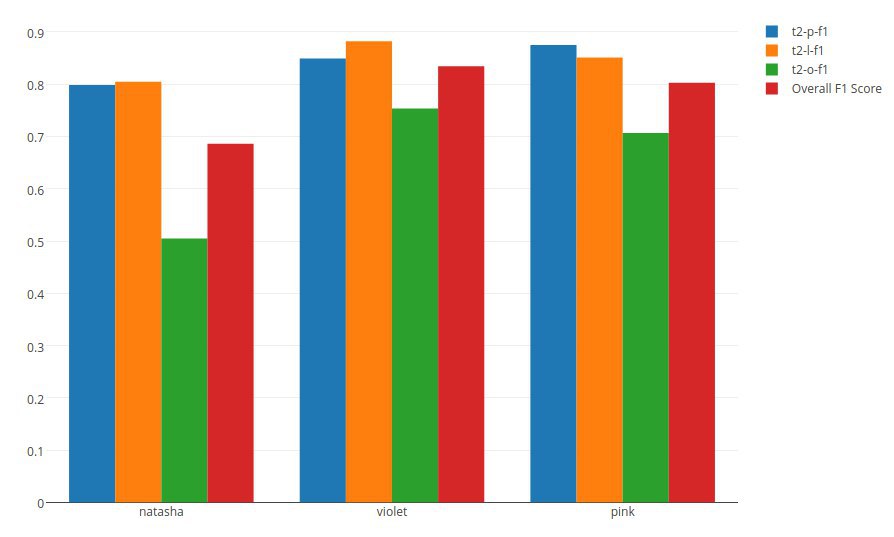
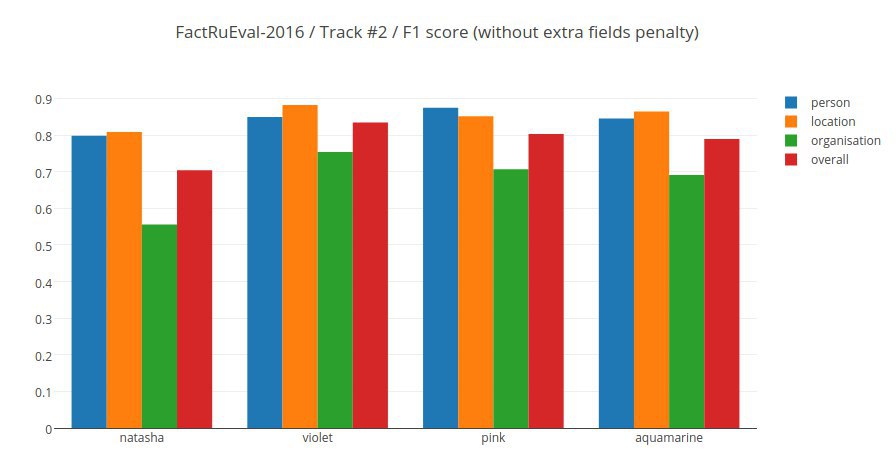
natasha - появилось разрешение кореференции для персон, топонимов и организаций, с более-менее приемлемым качествомDV
AK
DV
|
DV
>>> from yargy import Parser, Grammar
>>> from yargy.labels import gram
>>>
>>> text = 'звонить по +7(883)-332-32-42'
>>> grammar = Grammar(None, [
... {
... 'labels': [
... gram('PHONE'),
... ]
... }
... ])
>>>
>>> parser = Parser([grammar])
>>> matches = parser.extract(text)
>>> grammar, tokens = next(matches)
>>> tokens[0].value
'+7(883)-332-32-42'
dictionary не отрабатывает, но можно делать так:from yargy.labels import in_
PHONE_COUNTRY_PREFIX = {
'labels': [
in_([7, 8]),
],
}
...
AK
|
>>> from yargy import Parser, Grammar
>>> from yargy.labels import gram
>>>
>>> text = 'звонить по +7(883)-332-32-42'
>>> grammar = Grammar(None, [
... {
... 'labels': [
... gram('PHONE'),
... ]
... }
... ])
>>>
>>> parser = Parser([grammar])
>>> matches = parser.extract(text)
>>> grammar, tokens = next(matches)
>>> tokens[0].value
'+7(883)-332-32-42'
dictionary не отрабатывает, но можно делать так:from yargy.labels import in_
PHONE_COUNTRY_PREFIX = {
'labels': [
in_([7, 8]),
],
}
...
|
VP
|
Total grammars count?