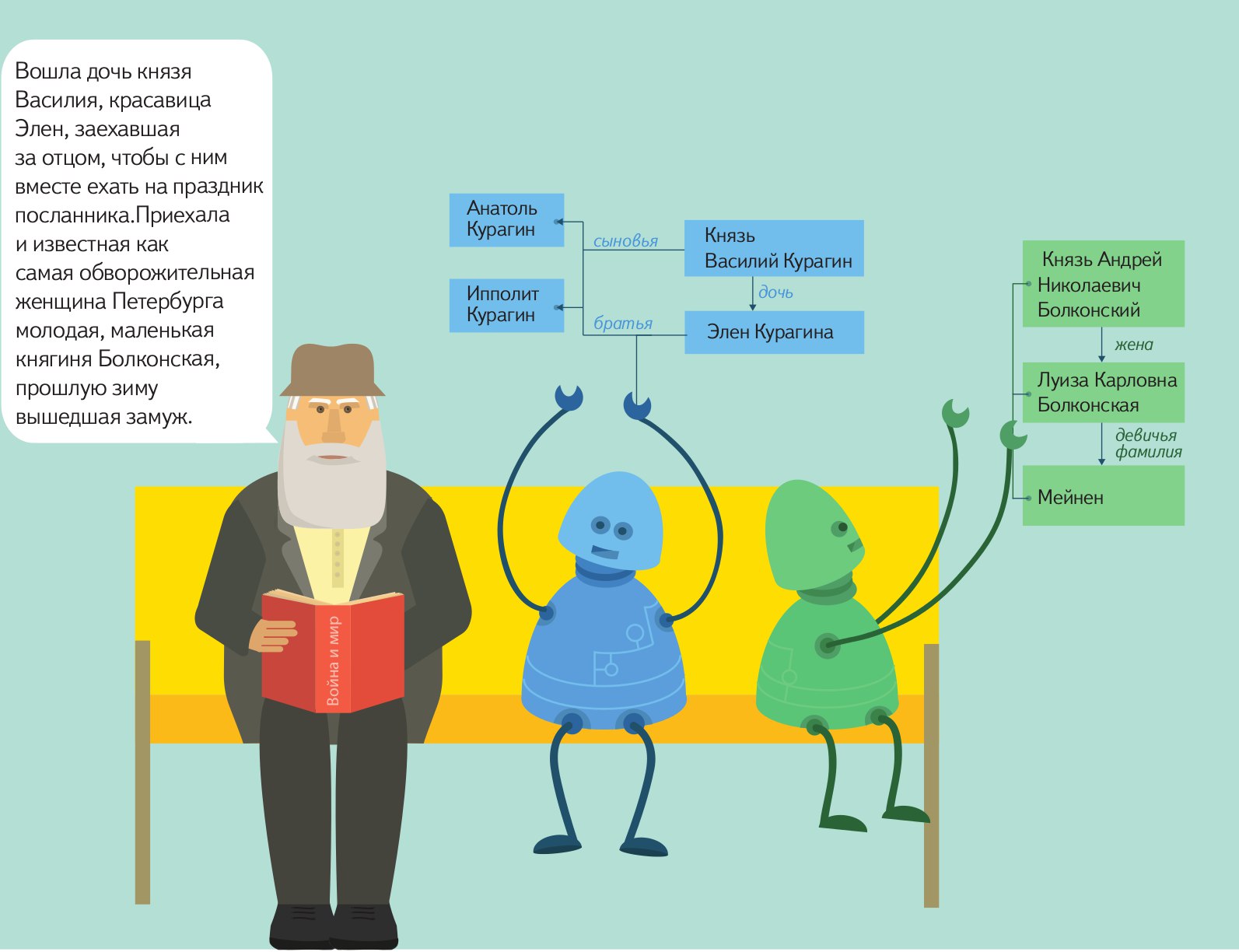
NT
не хотелось бы*
Size: a a a
NT
DV
DV
DV
AK
DV
DV
DV
DV
DV
AK
DV
DV
NT
NT
combinator = Combinator([Person, Organisation, Brand, Date, Location, Money])
matches = combinator.extract(text)
for grammar, match in combinator.resolve_matches(matches):
NT
NT