Ребята, если есть некий текст скажем статьи и в нем факты изложены и мне надо сгенерировать вопросы, чтобы эти факты были ответами, как это сделать?
Пример: "Самсунг выпустил ИИ людей неонов, они умеют делать то-то"
Мне надо автоматом кучку вопросов типа: Кто выпустил неонов? Что умеют делать неоны? Что выпустил самсунг? ну короче разные типы вопросов
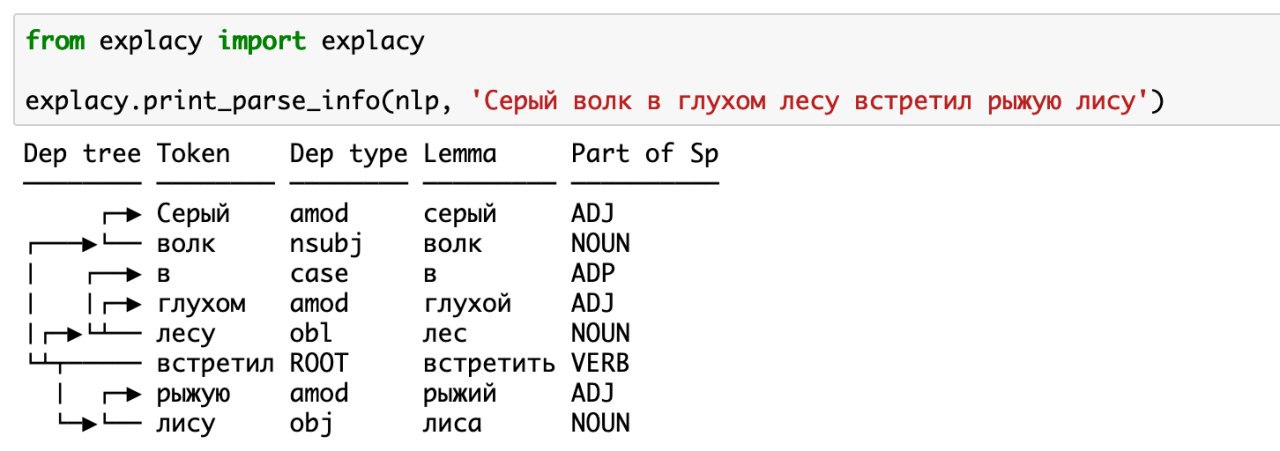
Я бы находил главные ключевые слова в тексте, для них строил дерево синтаксиса, и заменял ключевое слово на соответствующее ему вопросительное (nsubj -> "кто", obj -> "кто" или "что" в правильном падеже, в зависимости от одушевленности и т.д.). При этом можно обрезать часть предложения, не относящуюся к данной ветке. Может этот подход и не такой модный, как трансформеры, но качество должно быть хорошим для данной задачи. Сложности -- правильная обрезка, ошибки синтаксиса. А для правильного обнаружения ключевых слов -- надо делать textrank, или его упрощение, просто считать частоты (частоты лемм).