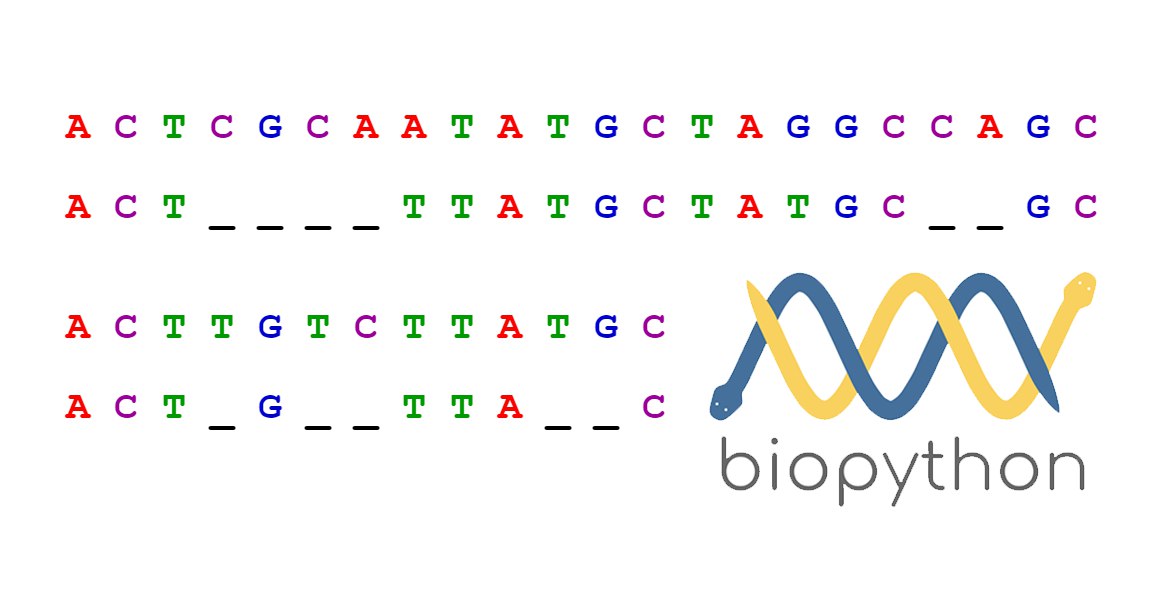
Коллеги, чем бы вы решали задачу:
Есть N последовательностей (текст) разных длин из алфавита A,B,C,D,E..., Например ADCA, ABCEBD, AB, DCE.
Надо выделить кластеры по похожести, учитывать порядок букв и длину цепочки.
Я как-то решал задачу с похожими объектами. Делал мешок нграмм, привязывал хим свойства к букве (но у меня длина была одинаковая), делал бинарное кодирование "какая буква идёт после какой".
Кажется, что данные раньше меня советы годные, раз тебе уже известно, из чего получать схожесть.