MS
подскажите, в какую сторону искать решение
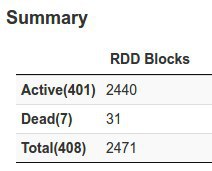
spark on yarn, streaming - рабоатет стрим и всё хорошо, но если одна из машинок на кластере зависает, спарк выставляет всем екзекьютерам на ней DEAD и потом никогда больше не использует её. Даже если перезагрузить машину - в стрим она не возвращается.
для того что бы заново использовать эту машину - нужно полностью перезапускать стрим
сейчас использую статическую аллокацию, - на днях думаю попробовать динамическую, но основной вопрос, как будут ли возвращатся машины в стрим?
если выводить
spark on yarn, streaming - рабоатет стрим и всё хорошо, но если одна из машинок на кластере зависает, спарк выставляет всем екзекьютерам на ней DEAD и потом никогда больше не использует её. Даже если перезагрузить машину - в стрим она не возвращается.
для того что бы заново использовать эту машину - нужно полностью перезапускать стрим
сейчас использую статическую аллокацию, - на днях думаю попробовать динамическую, но основной вопрос, как будут ли возвращатся машины в стрим?
если выводить
yarn node -list то машина в списке есть но число контейнеров на ней 0