Ω, [02.03.20 12:06]
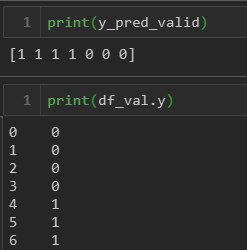
Добрый день. При бинарной классификации не сбалансированных данных у меня f1 практически 90% на тестовых данных. Затем беру валидационные данные(алгоритм векторизации тот же самый что и с обучающей и тестовой выборкой) и провожу классификацию. При этом f1=0, данные были классифицированы с обратными значениями(0й класс определился как 1й и 1й класс как 0й). Валидационные данные после векторизации проверил - 1му классу соот-т именно 1, с 0ым так же все ок. Попробовал поменять метки классов перед классификацией(0 на 1, 1 на 0) - f1 на уровне 99%. Что я сделал не так?