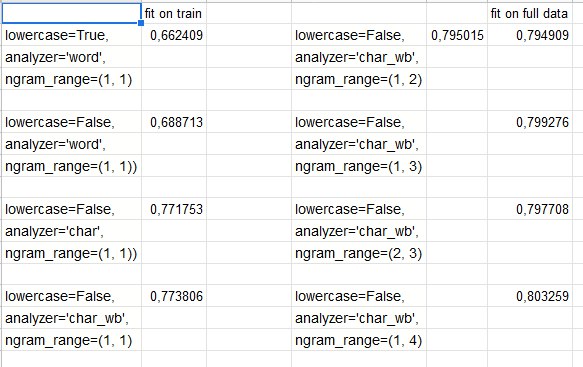
хер его знает) писалось в 3 часа ночи
я могу только предполагать
—
Основная идея:
доумножили предсказания (y_pred) которые были получены моделью (вне post-processing) на некоторые коэффициенты
мы знаем что в датасете есть дубликаты вопросов
мы знаем что одни и те же дубликаты могут быть как и в y==1 так и в y==0
соотвественно для таких дубликатов мы хотели бы откорректировать предсказания модели
так же хотели бы их откорректировать и для "near-дубликатов"
т.е. мы юзаем некое априорное знание, которого нету у модели, по сути делая корректировку "исходной" модели
almost/exact я думаю self-explanatory
В трейне есть что-то похожее ? ок, докидываем (как в позитивную, так и негативную сторону)
с knn посложнее
1) тут мы задали векторное пространтсов,
2) меру близости
3) нашли расстояние в этом прострастве до ближайшего примера для X_train[y==0] и X_train[y==0]
4) высчитали разницу расстояний
Примеры:
- если и в трейне_pos и трейне_neg есть один и тот же объект (дубликат) - разница равна нулю - пердсказания не меняются
- если это не полные дубликаты, разница будет не нулевой, вытягивает предсказания в эту сторону