PD
Через какое действие она будет возникать?
Сверка по батчу утреннему? Перезапись + TL из write-model?
Сверка по батчу утреннему? Перезапись + TL из write-model?
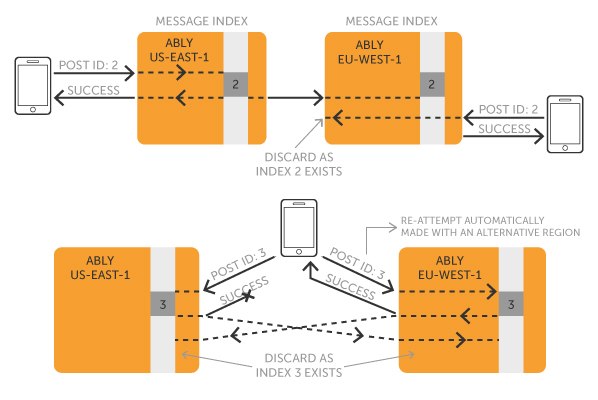
Хм, а как батчи связаны с идемпотентностью? Это скорее про обеспечение "как минимум раз" (что та же кафка обеспечивает без проблем).
Мы вроде про то, что вместо "exactly once" проще реализовать идемпотентность+"at least once"
Мы вроде про то, что вместо "exactly once" проще реализовать идемпотентность+"at least once"