VS
В случае всяких mssql (ssis) и тд это препросчитанные данные, если говорим про molap
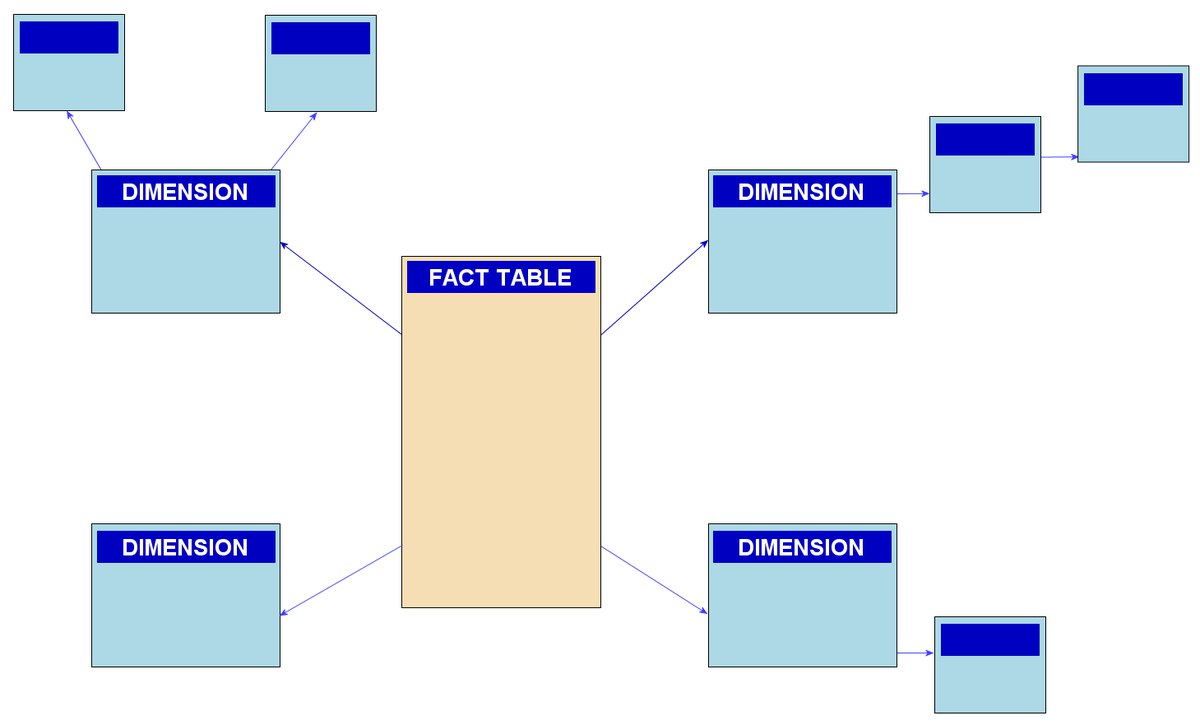
Или в случае какой вертики и терадаты snowflake схема и rolap, но вопросы что нужно делать джойны на больших объемах, что не позволяет в 1 секунду на запрос уложиться
В случае всяких пинотов/друид/клик данные храняться лишь в частично агрегированном виде, но за счёт архитектуры и структур данных могут считаться на лету и выдают время ниже 1с
Но нужно понимать что данные зачастую там тайм серии и обновлять сложно
Или в случае какой вертики и терадаты snowflake схема и rolap, но вопросы что нужно делать джойны на больших объемах, что не позволяет в 1 секунду на запрос уложиться
В случае всяких пинотов/друид/клик данные храняться лишь в частично агрегированном виде, но за счёт архитектуры и структур данных могут считаться на лету и выдают время ниже 1с
Но нужно понимать что данные зачастую там тайм серии и обновлять сложно
а почему вы сравниваете разные базы с точки зрения джойнов?