Это же вообще доступно, насколько помню в платной раньше был jfr бекпортнут, но сейчас он и в опенждк уже есть (не помню точно номер, 242 вроде, летом вышла)
медленнее - потому что будет меньше тасков и каждый из них будет выполняться дольше. И неравномерно к тому же. Сам стейдж coalesce как правило намного быстрее repartition
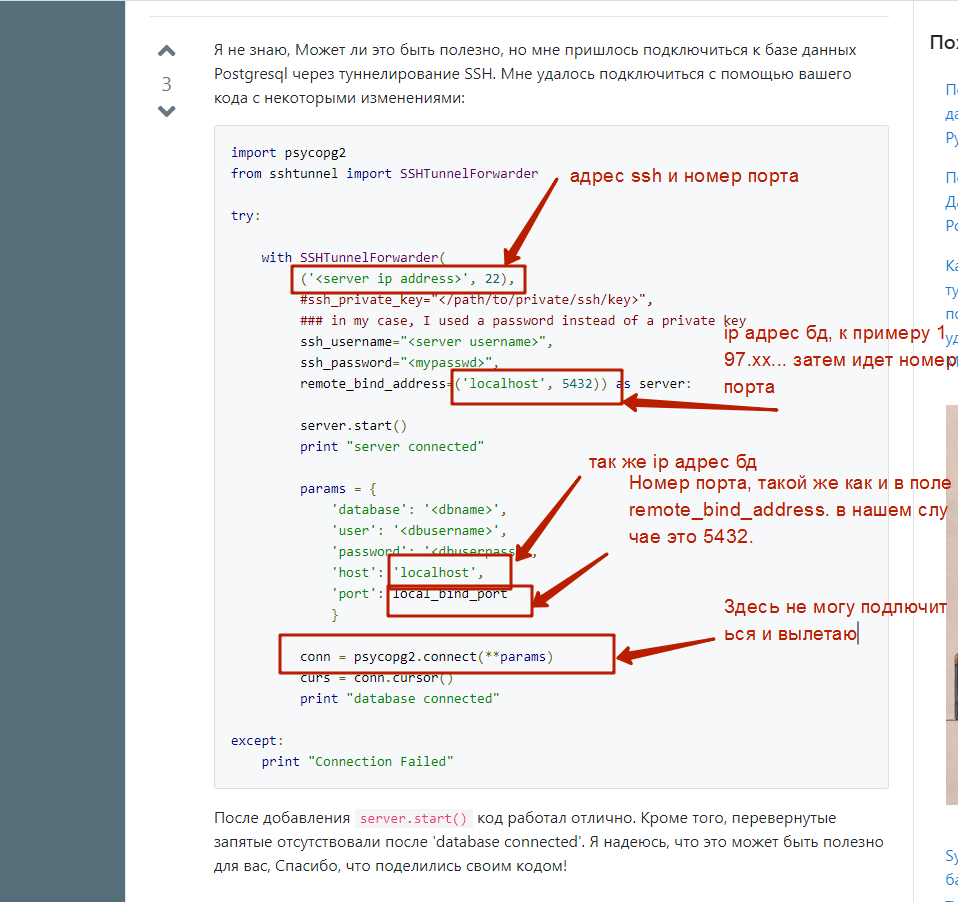
Всем добрый вечер. Пытаюь к Postgre подлючится через ssh. Нашел такой пример. ssh тунель создается нормально, но к post не могу подлючится. Кто может подсказать, что не так делаю?
Всем добрый вечер. Пытаюь к Postgre подлючится через ssh. Нашел такой пример. ssh тунель создается нормально, но к post не могу подлючится. Кто может подсказать, что не так делаю?
Всем добрый вечер. Пытаюь к Postgre подлючится через ssh. Нашел такой пример. ssh тунель создается нормально, но к post не могу подлючится. Кто может подсказать, что не так делаю?
Надо разрешить подключение всконфиг файле с желаемых хостов, либо со всех
Привет! Пробую настроить spark-submit на удаленный кластер с помощью Big Data Tools в InteliJ. Все отлично работает. Хочу добавть в before lauch сборку через sbt package. В итоге отрабатывает только сборка и все. (перекидывание джарника и spark-submit не стартует). Есть идеи?