AK
What all technology i should start with?
Please help
Please help
Size: a a a
AK
AB
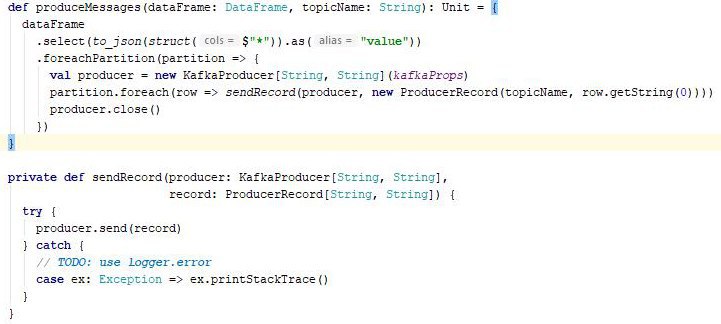
df.write
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.save()
AC
YI
YI
GP
SZ
B
СХ
СХ
СХ
R
AY
VS
B
AB
AB
A
A