Уже 16 июля пройдет вебинар #ODSC “Kubeflow, MLFlow and Beyond — Augmenting ML Delivery” ❓Когда? 16 июля, 1 pm – 2 pm EST. Спикер: Степан Пушкарев, CTO of Provectus
Степан расскажет, как спроектировать эффективный ML процесс, про применение в нём различных open source инструментов способствующих автоматизации и воспроизводимости.
там про питон? spark? tensor? спецом открыл фейсбук и ссылку, стэк вообще не указан...
Будут использованы Kubeflow и Hydrosphere. Касательно MLFlow и Kubeflow нельзя сказать, что их можно сравнить. Они выполняют относительно разный функционал, и вместе дополняют друг друга.
Будут использованы Kubeflow и Hydrosphere. Касательно MLFlow и Kubeflow нельзя сказать, что их можно сравнить. Они выполняют относительно разный функционал, и вместе дополняют друг друга.
Ну так-то они все (MLFlow, Hydrosphere, Kubeflow) чем-то отличаются, поэтому интересно посмотреть, что спикер включил в референс и какие задачи делегировал. Ок, спасибо!
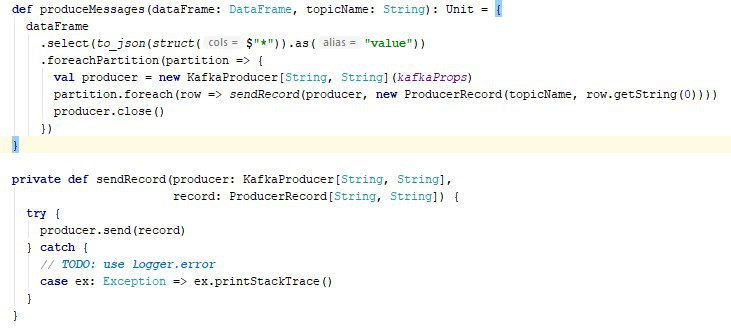
Привет всем, Может кто помочь с интеграцией Spark/Kafka 1. Надо загрузить DataFrame в Kafka (т.е передать messages). Мы не используем Spark Streaming. Работаем со SparSQL 2.1.0. Есть ли у кого-то пример как это сделать, потому что сейчас делаю так и не уверен что это хороший solution: