



A
Size: a a a
2019 June 21

S
хмхм. надо потестить вообщем. так непонятно
A
@barloc
с большим потоком апдейтов сразу же меняйте дефолтные настройки:
- включить мульти wal (по умолчанию пишет в один файл на регионсервер, врубаете файл на регион) (https://www.cloudera.com/documentation/enterprise/5-8-x/topics/admin_configure_multiwal.html )
- если на hdfs настроены разные tier уровни с ssd и без, то указать чтобы wal кидали на ссд https://www.cloudera.com/documentation/enterprise/5-13-x/topics/admin_hbase_wal_storage_policy.html ( Warning: ONE_SSD mode has not been thoroughly tested with HBase and is not recommended. - хоть в доках и написано предупреждение, но УМВР)
- поменять дефолтное значение для минор компакции (3 региона) на что-то более адкеватное, например 10-15. при многих апдейтах не придется по десять раз переливать одно и тоже, а сразу более адекватно собирать будете
- ну и кеши настроить разные, но тут с ходу вот так не вспомню =)
если не сделаете то сразу просядете на записе из-за блокировок на wal
потом hdfs начнете нагибать на почти постоянным компакшеном
с большим потоком апдейтов сразу же меняйте дефолтные настройки:
- включить мульти wal (по умолчанию пишет в один файл на регионсервер, врубаете файл на регион) (https://www.cloudera.com/documentation/enterprise/5-8-x/topics/admin_configure_multiwal.html )
- если на hdfs настроены разные tier уровни с ssd и без, то указать чтобы wal кидали на ссд https://www.cloudera.com/documentation/enterprise/5-13-x/topics/admin_hbase_wal_storage_policy.html ( Warning: ONE_SSD mode has not been thoroughly tested with HBase and is not recommended. - хоть в доках и написано предупреждение, но УМВР)
- поменять дефолтное значение для минор компакции (3 региона) на что-то более адкеватное, например 10-15. при многих апдейтах не придется по десять раз переливать одно и тоже, а сразу более адекватно собирать будете
- ну и кеши настроить разные, но тут с ходу вот так не вспомню =)
если не сделаете то сразу просядете на записе из-за блокировок на wal
потом hdfs начнете нагибать на почти постоянным компакшеном
S
@barloc
с большим потоком апдейтов сразу же меняйте дефолтные настройки:
- включить мульти wal (по умолчанию пишет в один файл на регионсервер, врубаете файл на регион) (https://www.cloudera.com/documentation/enterprise/5-8-x/topics/admin_configure_multiwal.html )
- если на hdfs настроены разные tier уровни с ssd и без, то указать чтобы wal кидали на ссд https://www.cloudera.com/documentation/enterprise/5-13-x/topics/admin_hbase_wal_storage_policy.html ( Warning: ONE_SSD mode has not been thoroughly tested with HBase and is not recommended. - хоть в доках и написано предупреждение, но УМВР)
- поменять дефолтное значение для минор компакции (3 региона) на что-то более адкеватное, например 10-15. при многих апдейтах не придется по десять раз переливать одно и тоже, а сразу более адекватно собирать будете
- ну и кеши настроить разные, но тут с ходу вот так не вспомню =)
если не сделаете то сразу просядете на записе из-за блокировок на wal
потом hdfs начнете нагибать на почти постоянным компакшеном
с большим потоком апдейтов сразу же меняйте дефолтные настройки:
- включить мульти wal (по умолчанию пишет в один файл на регионсервер, врубаете файл на регион) (https://www.cloudera.com/documentation/enterprise/5-8-x/topics/admin_configure_multiwal.html )
- если на hdfs настроены разные tier уровни с ssd и без, то указать чтобы wal кидали на ссд https://www.cloudera.com/documentation/enterprise/5-13-x/topics/admin_hbase_wal_storage_policy.html ( Warning: ONE_SSD mode has not been thoroughly tested with HBase and is not recommended. - хоть в доках и написано предупреждение, но УМВР)
- поменять дефолтное значение для минор компакции (3 региона) на что-то более адкеватное, например 10-15. при многих апдейтах не придется по десять раз переливать одно и тоже, а сразу более адекватно собирать будете
- ну и кеши настроить разные, но тут с ходу вот так не вспомню =)
если не сделаете то сразу просядете на записе из-за блокировок на wal
потом hdfs начнете нагибать на почти постоянным компакшеном
спасибо )
S
а опыт получен на насколько большом потоке?
A
снепшоты опасны тем что их нужно дропать, так как они держат место, хотя проде как и данные удалены
в общем те же проблемы что и с файлсистемами zfs/btrfs: диски почистили, а место не освободилось 😉
в общем те же проблемы что и с файлсистемами zfs/btrfs: диски почистили, а место не освободилось 😉
A
ну запись+чтение за миллион был в секунду
A
но после всех оптимизаций все было нормально и кластер бы и больше выдал
S
как раз то что надо
SZ
神風
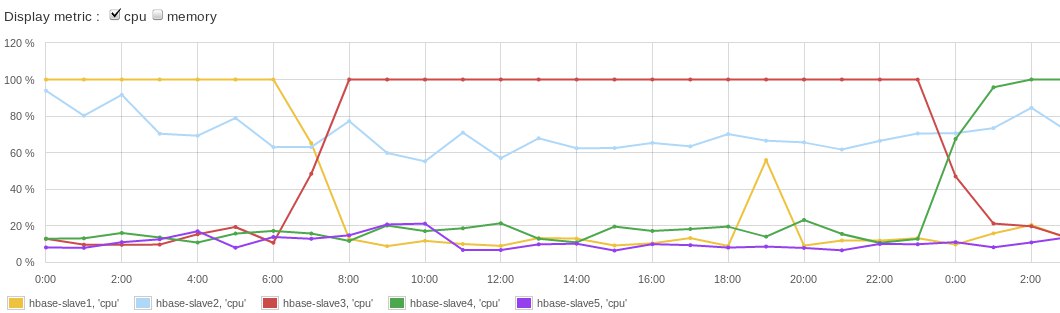
Нельзя. Есть ощущение, что падает регион от того, что сразу несколько экзекутеров пишут в один регион сервер. Установил heap на регион сервере в 10гб, пока не падает. Не многовато ли?
Нужно избегать монотонно возрастающих ключей, почитайте вот тут подробнее https://sematext.com/blog/hbasewd-avoid-regionserver-hotspotting-despite-writing-records-with-sequential-keys/
DP
FAILED: SemanticException [Error 10294]: Attempt to do update or delete using transaction manager that does not support these operations.
Hive как я понимаю не поддерживает по умолчанию update и delete, что посоветуете для исправления ?
Hive как я понимаю не поддерживает по умолчанию update и delete, что посоветуете для исправления ?
AP
Если нужен ACID и сопутствующие операции update-delete, его можно включить. Но там много нюансов.
DP
тут прочитал что надо создать таблици таким образом:
DROP TABLE IF EXISTS hello_acid;
CREATE TABLE hello_acid (key int, value int)
PARTITIONED BY (load_date date)
CLUSTERED BY(key) INTO 3 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true');
DROP TABLE IF EXISTS hello_acid;
CREATE TABLE hello_acid (key int, value int)
PARTITIONED BY (load_date date)
CLUSTERED BY(key) INTO 3 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true');
S
у вас не очень юзкейс хайва и будет больно
DP
что делать если use-case такой что нужно обновлять записи по id ?
DP
или что то вроде merge into (как в HBase "put")
AP
Нужны настройки на сервисе (типа ACID enabled, transaction manager и т.п.). Послеэтого или сразу создавтаь ACID таблицу, либо можно даже ALTER в транзакционную (но не наоборот). Но @barloc выше правильно говорит.
S
или что то вроде merge into (как в HBase "put")
с точечным апдейтом - все тлен. как вариант - апдейтить сразу все ) большим куском - файлом
S
Alexander Piminov
Если нужен ACID и сопутствующие операции update-delete, его можно включить. Но там много нюансов.
вы еще мучаетесь? )
AP
вы еще мучаетесь? )
Ну LLAP, похоже, окончательно починился, HW признал, что есть проблема в параметрах JVM. А так у нас HDP Hive и сервисы в AWS соседствуют нормально...может, от Hive откажутся, в итоге.