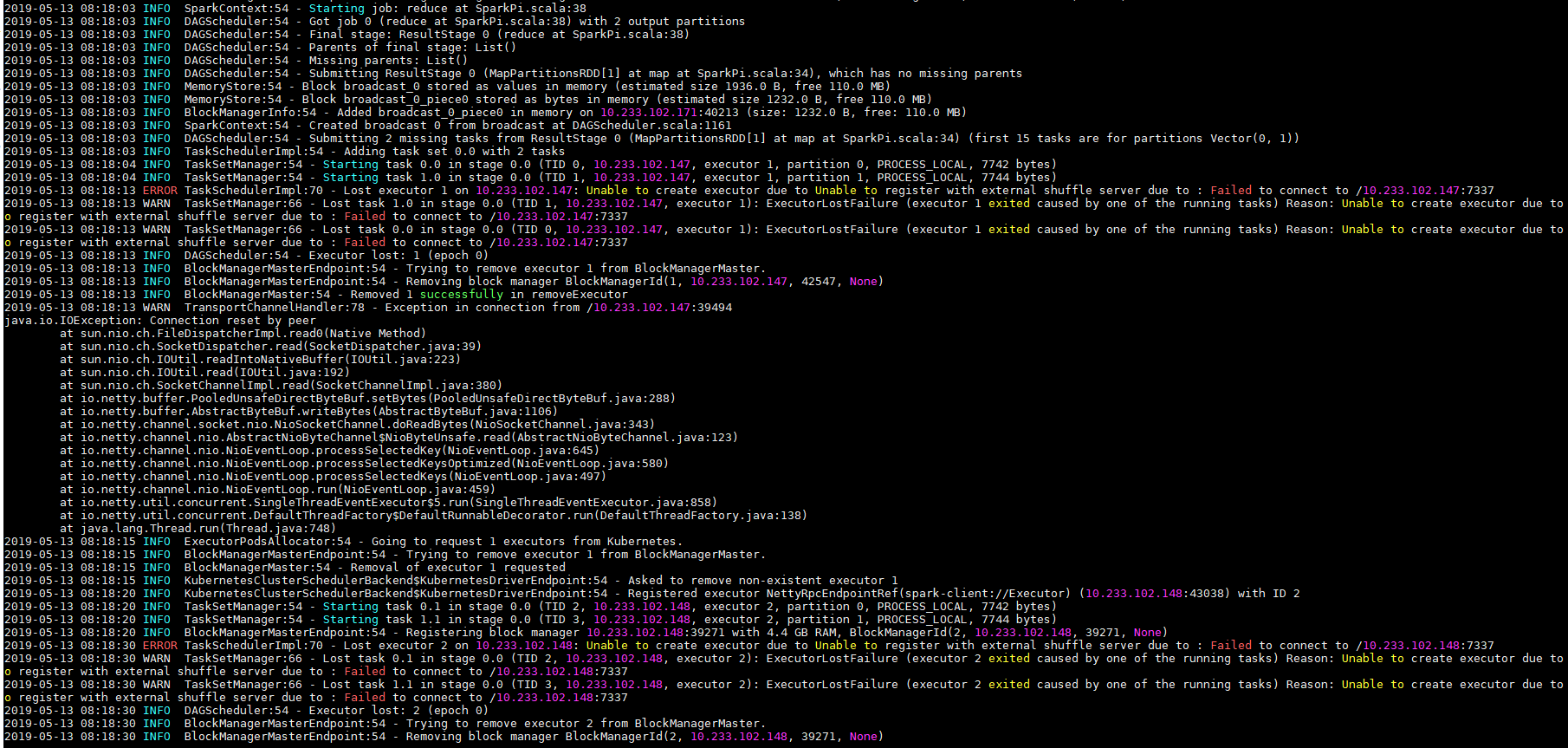
AZ
сейчас у меня вопрос больше по поводу возможно ли в приципе подобное?. Увеличить количесвто ресурсов мы всегда успеем)
ну делать мониторинг лага это прям много движущихся частей (хотя у меня есть клиент у которого автоскейлеры стоят на лаг.. думаю если вашим потребителям данным из кассандры не важна задержка обновления данных - то батч по крону это лучший вариант