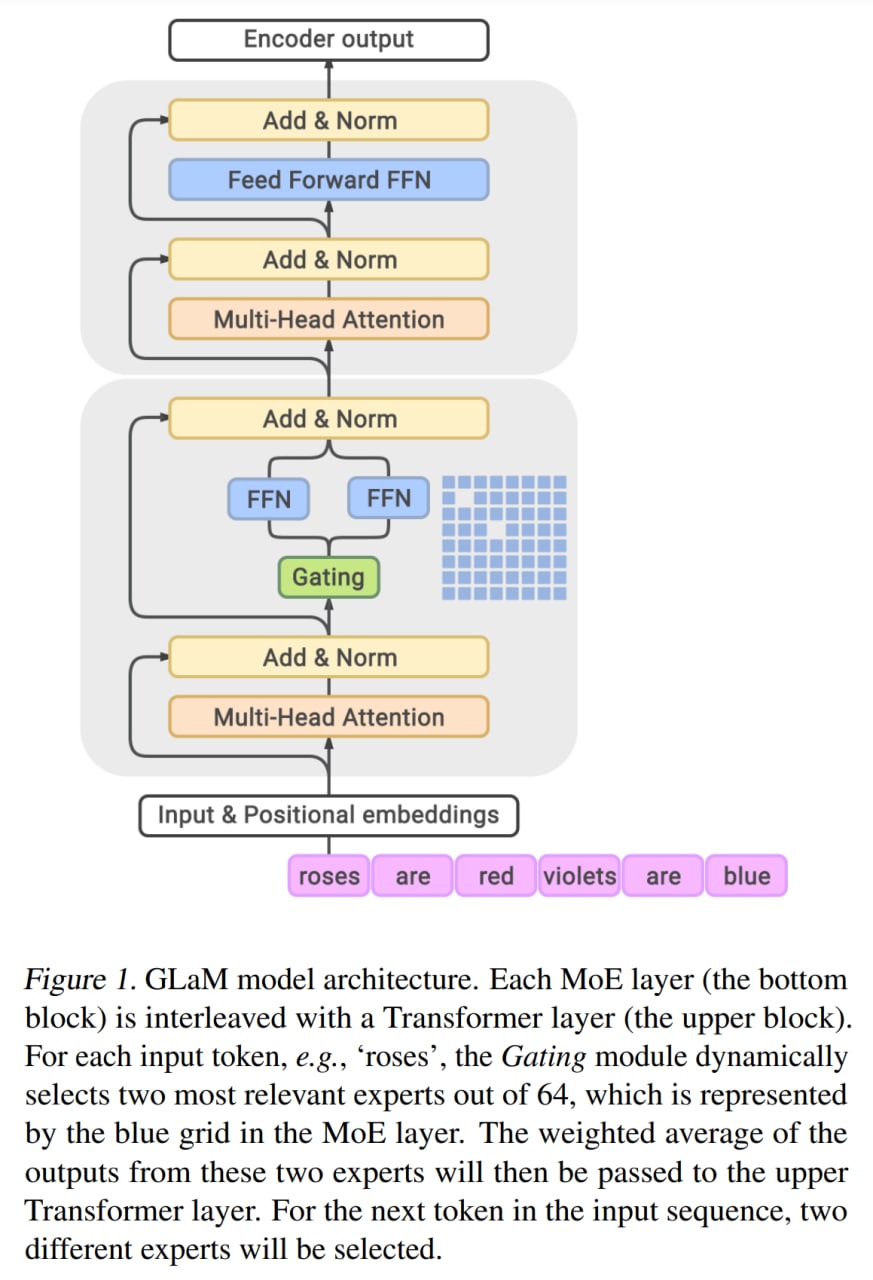
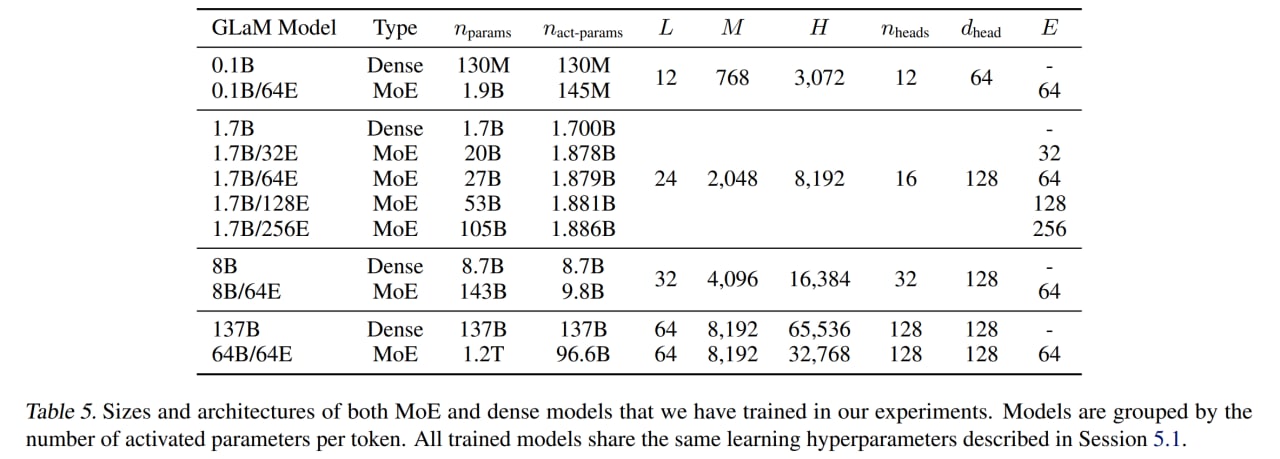
При обучении всё это распределяется по кластеру TPUv4 (для самой большой модели использовались 1024 TPU чипа), эксперты с одинаковыми индексами в разных слоях живут на одних и тех же устройствах, чтобы граф вычислений был одинаковым для каждого MoE слоя. В шардинге полагаются на компилятор GSPMD (https://arxiv.org/abs/2105.04663). Используется дополнительный MoE loss из работы про GShard, чтобы более равномерно раскидывались токены по экспертам. Авторы добились стабильного обучения сетей разного размера с одним набором гиперпараметров.
Для оценки моделей отобрали 29 датасетов (8 для задач NLG, 21 для NLU). Это оригинальный набор из 42 датасетов, на котором оценивали GPT-3 (https://t.me/gonzo_ML/305), с отброшенными 7 синтетическими задачами на арифметику и т.п., а также 6 датасетами для машинного перевода. Сравнивают на zero-shot и one-shot.
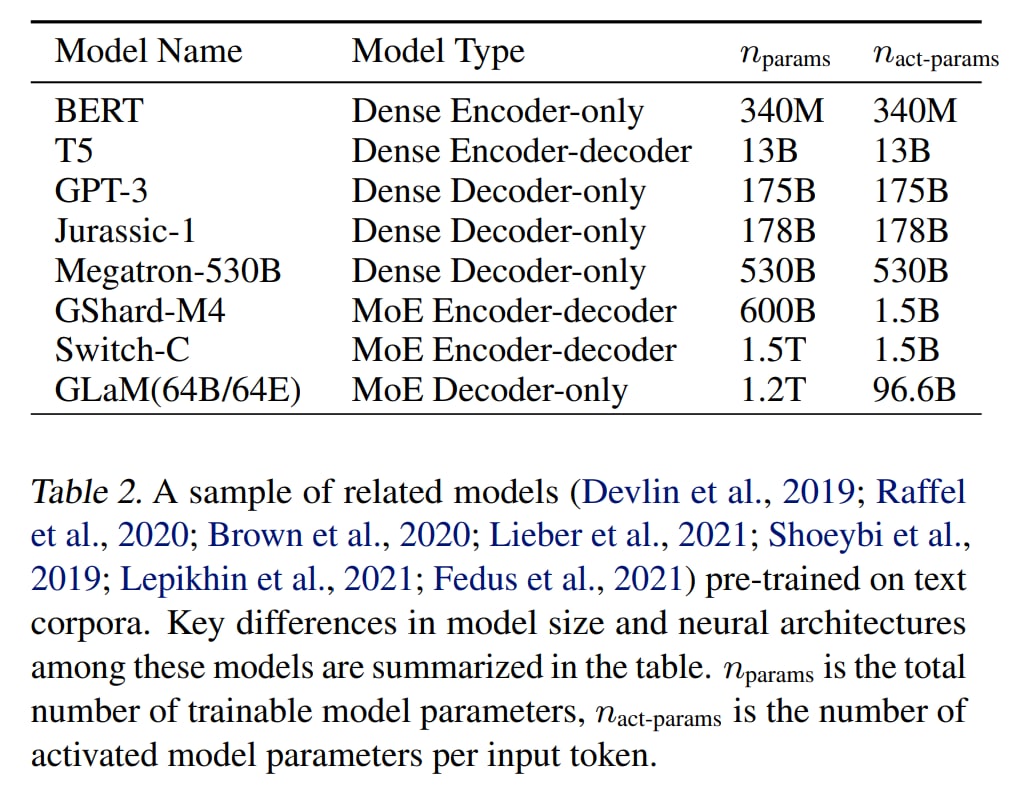
Сравнивают разные модели с упором на одинаковое количество вычислений или количество активных параметров на токен.
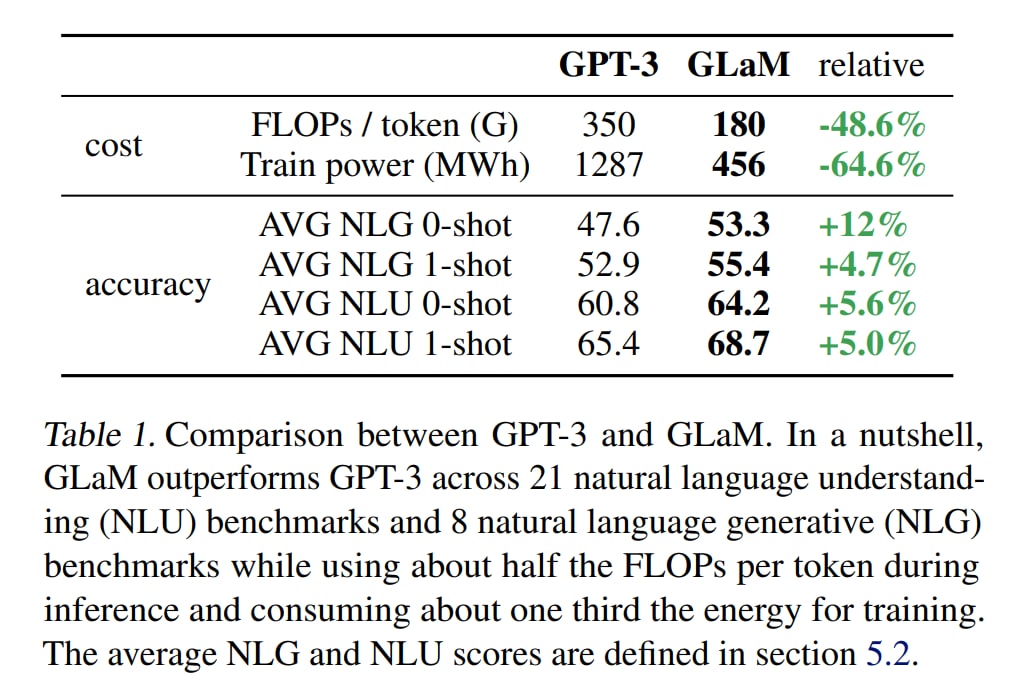
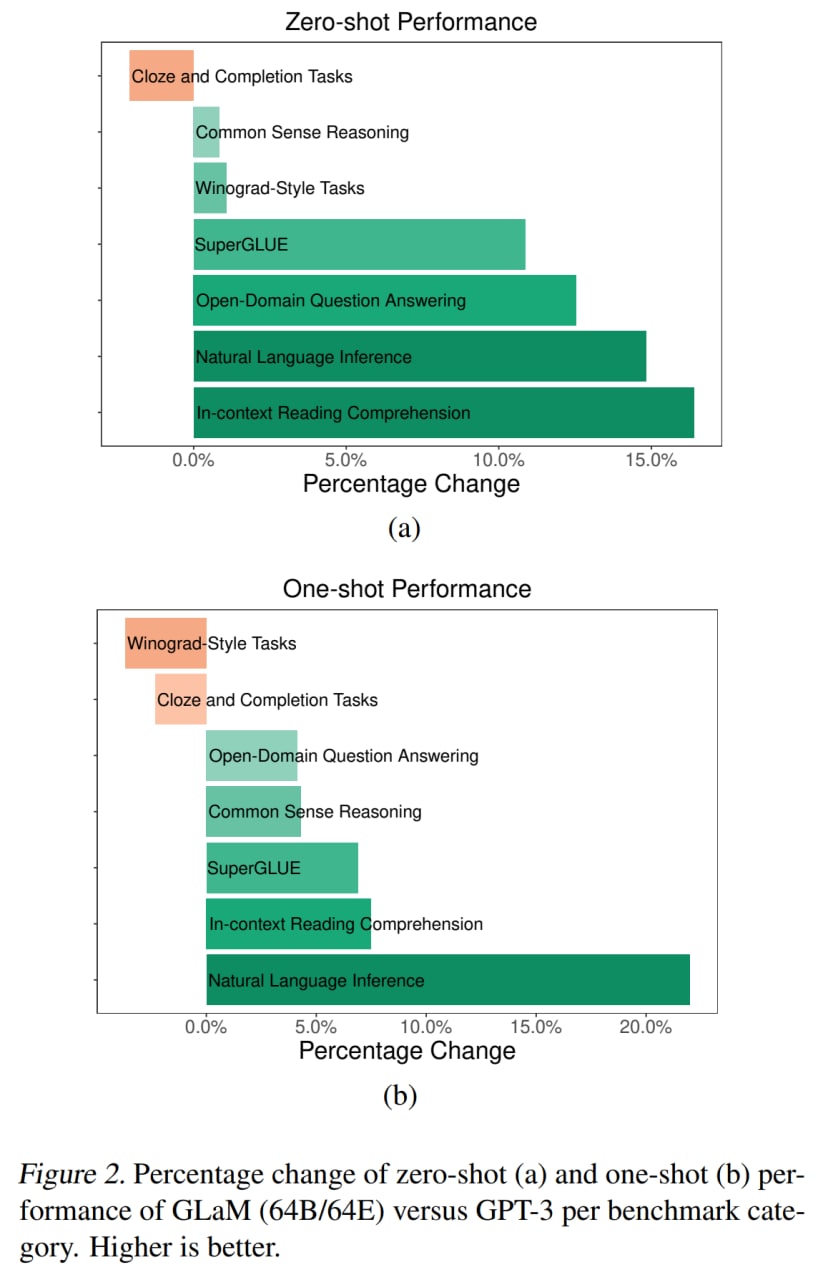
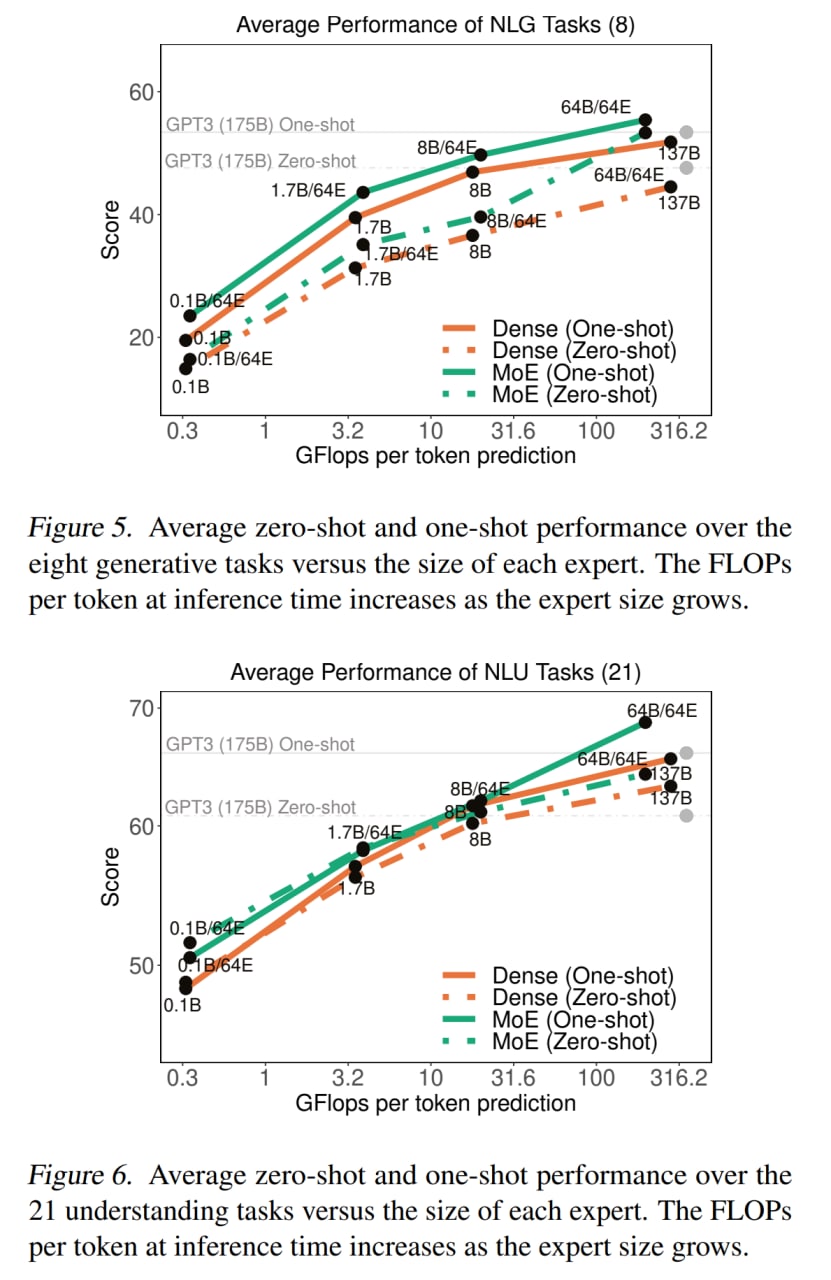
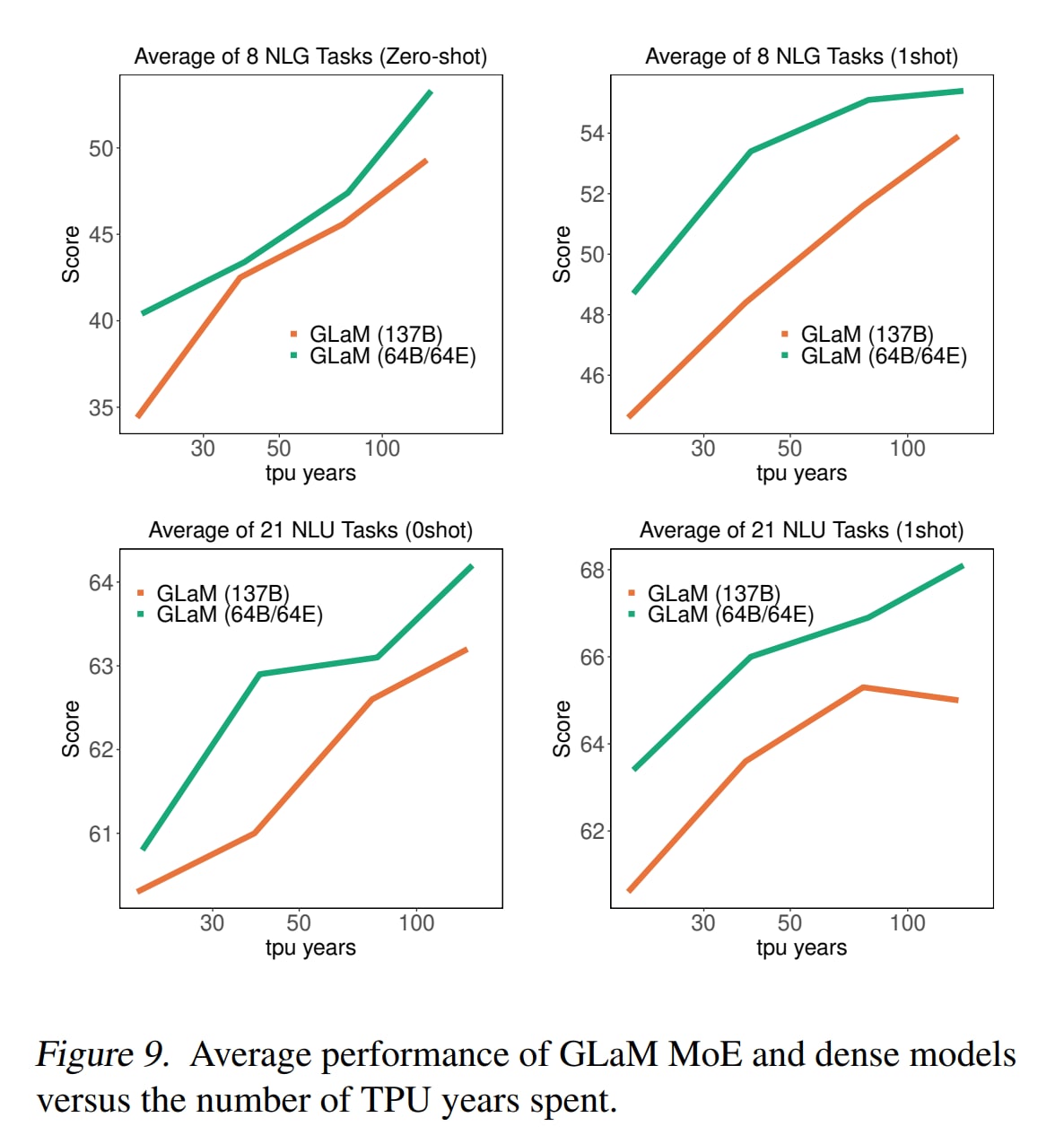
В целом по 5 из 7 категорий задач GLaM заметно превзошла GPT-3. При этом GLaM 64B/64E (самая большая) с 96.6B активных весов на токен (у самой большой GPT-3 их 175B) во время инференса требует примерно в два раза меньше вычислений для того же входа.
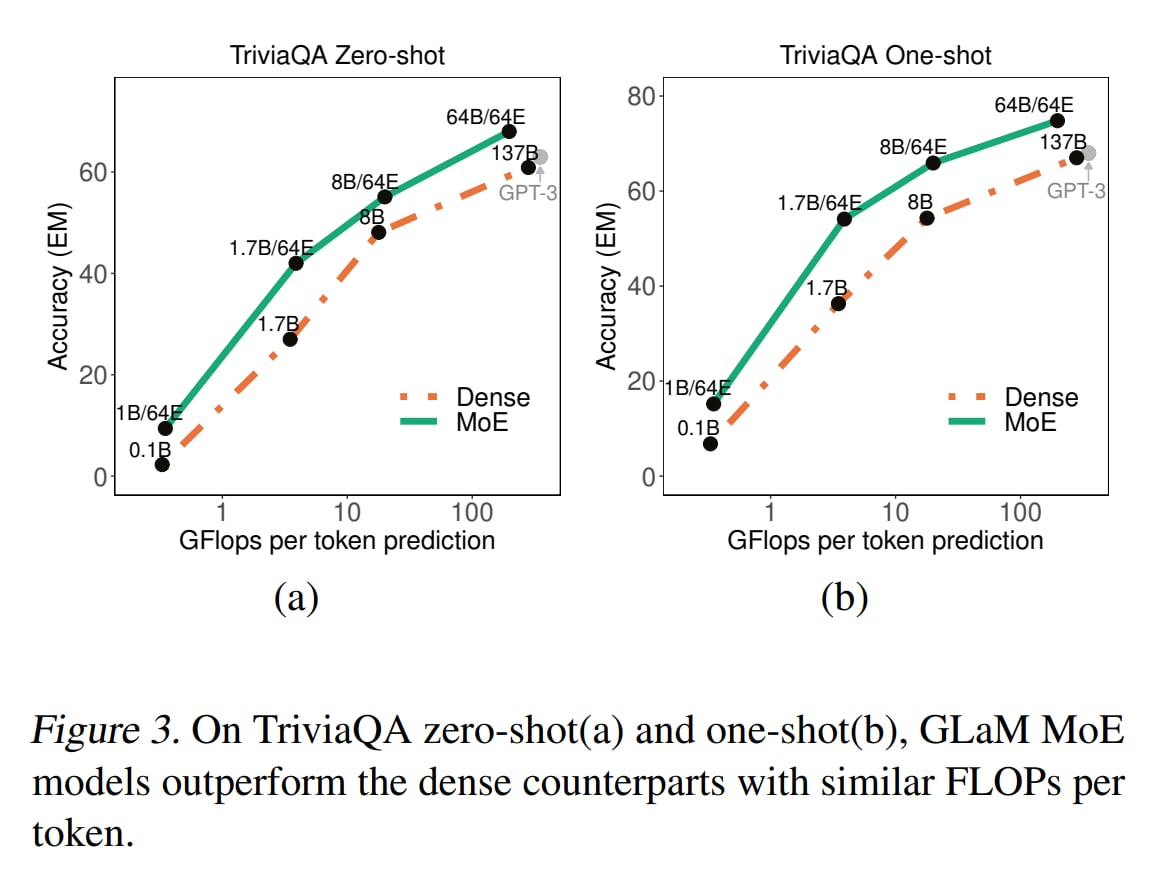
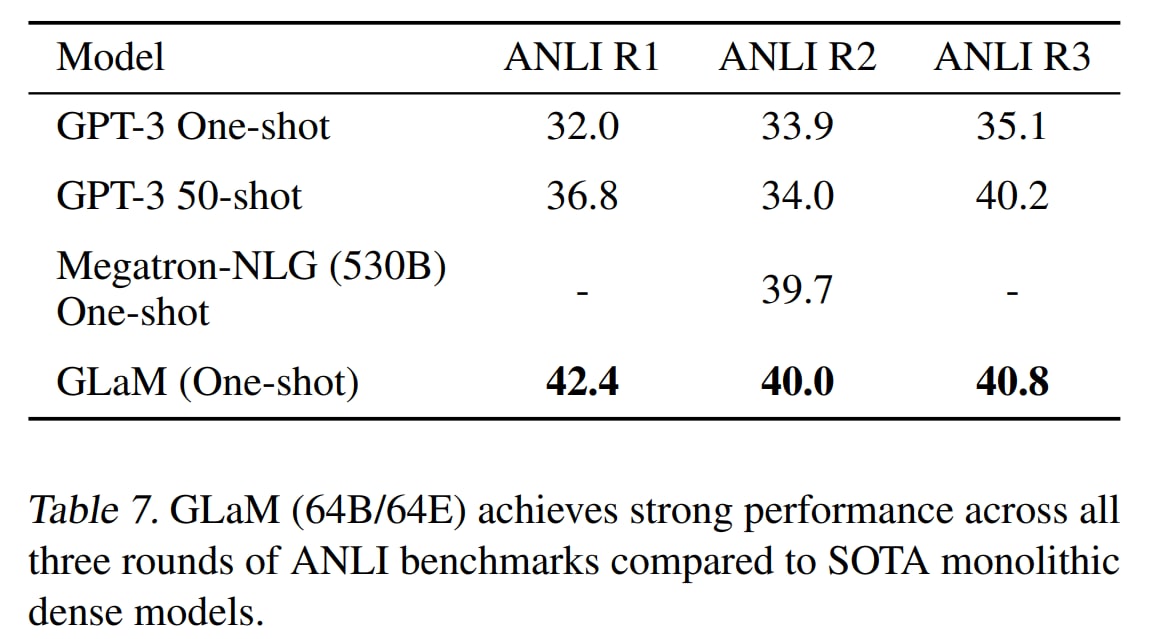
На TriviaQA побили старую SoTA. На ANLI дают качество выше, чем у Megatron-NLG с 530B параметров, при этом требуя менее 20% вычислений последнего.
Авторы также поисследовали bias’ы модели, показали, что она установила SoTA на WinoGender, превзойдя GPT-3.
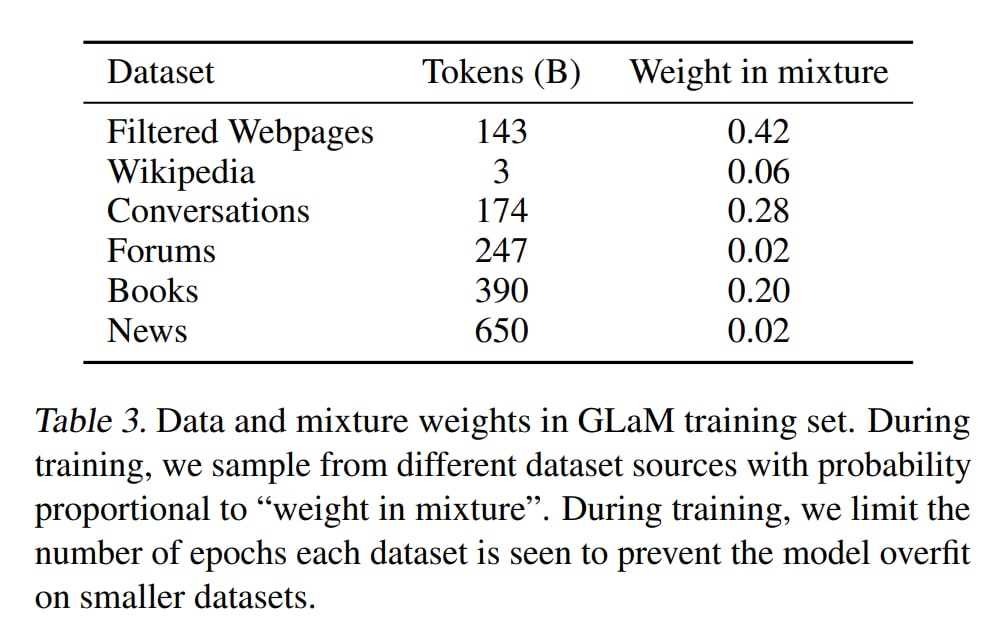
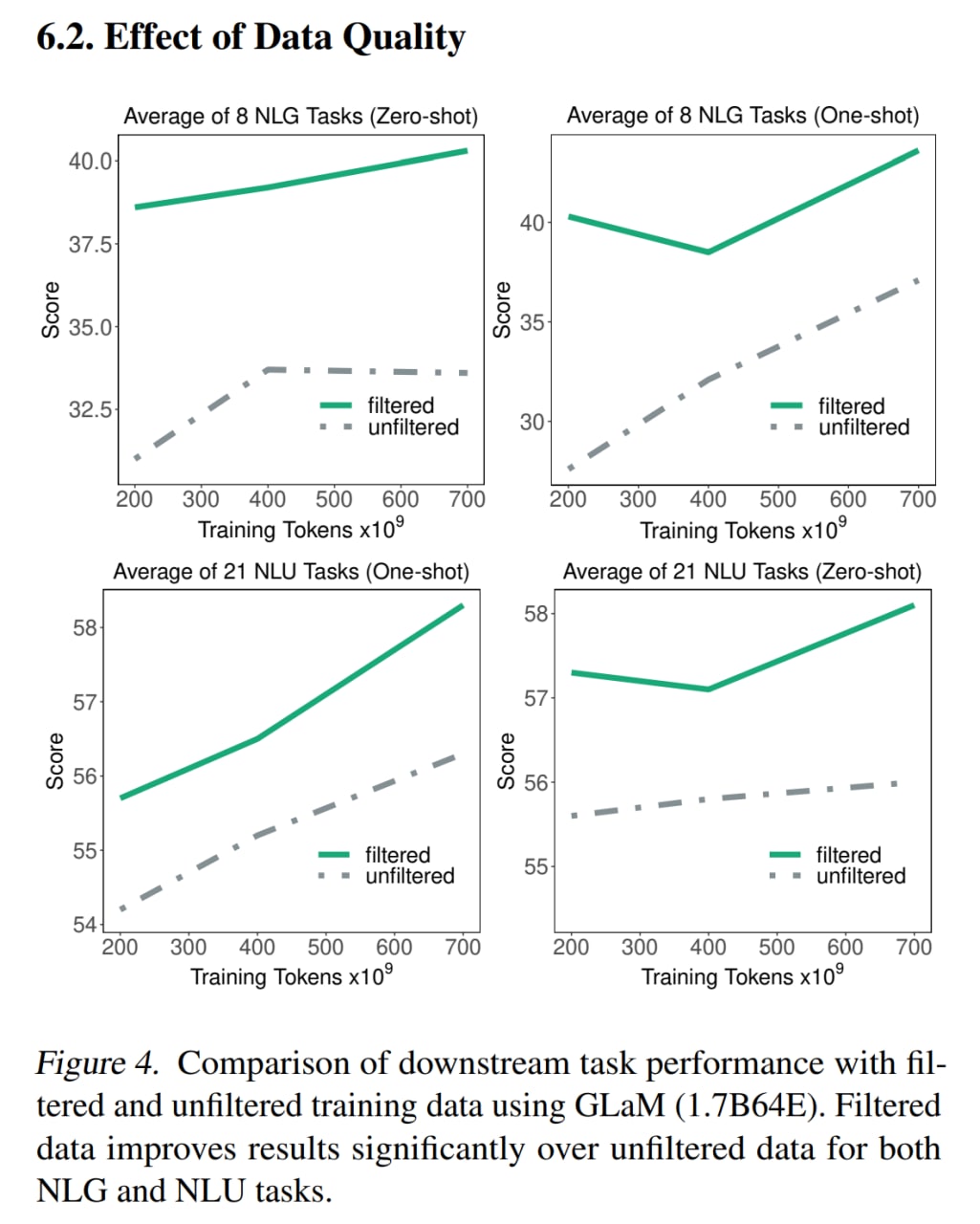
Отдельно померяли влияние качества данных, показали, что более качественные фильтрованные данные крайне важны, объёмом до этих цифр так просто не доберёшь.
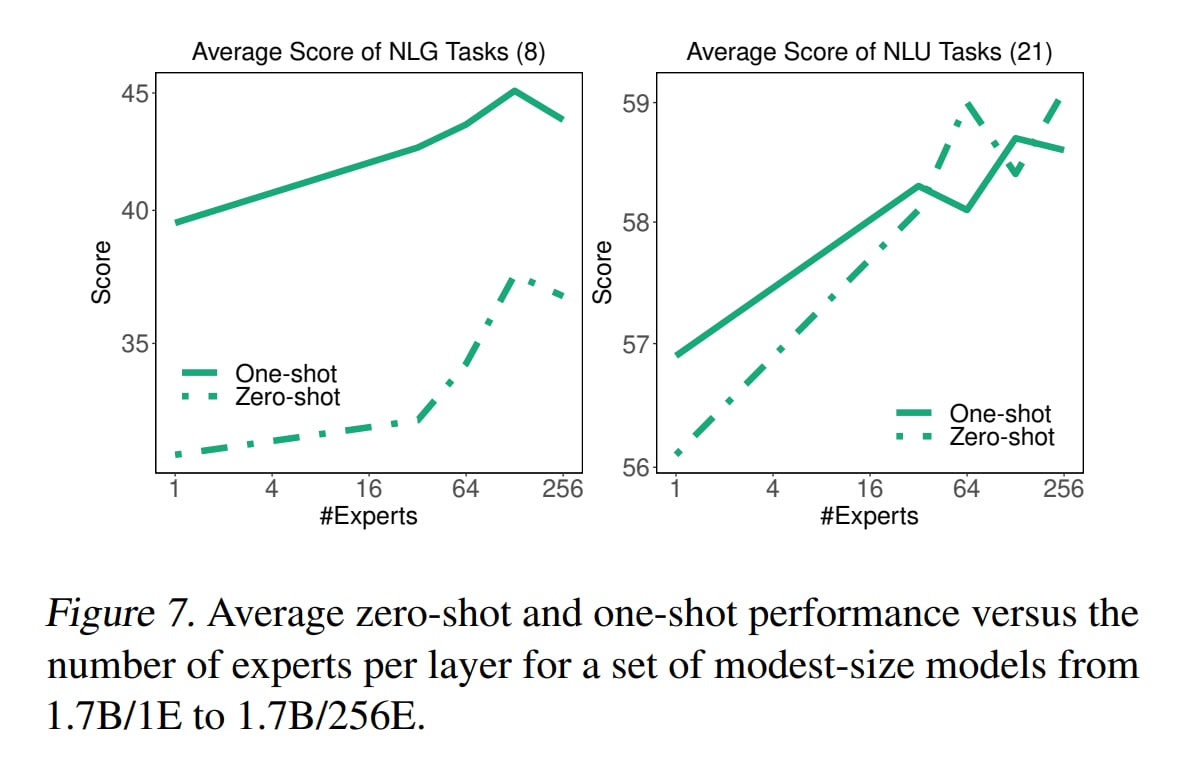
И с ростом сети (и соответственно ростом размера отдельного эксперта), и с ростом числа экспертов, качество увеличивается.
По сравнению с dense моделями у MoE видны два преимущества.
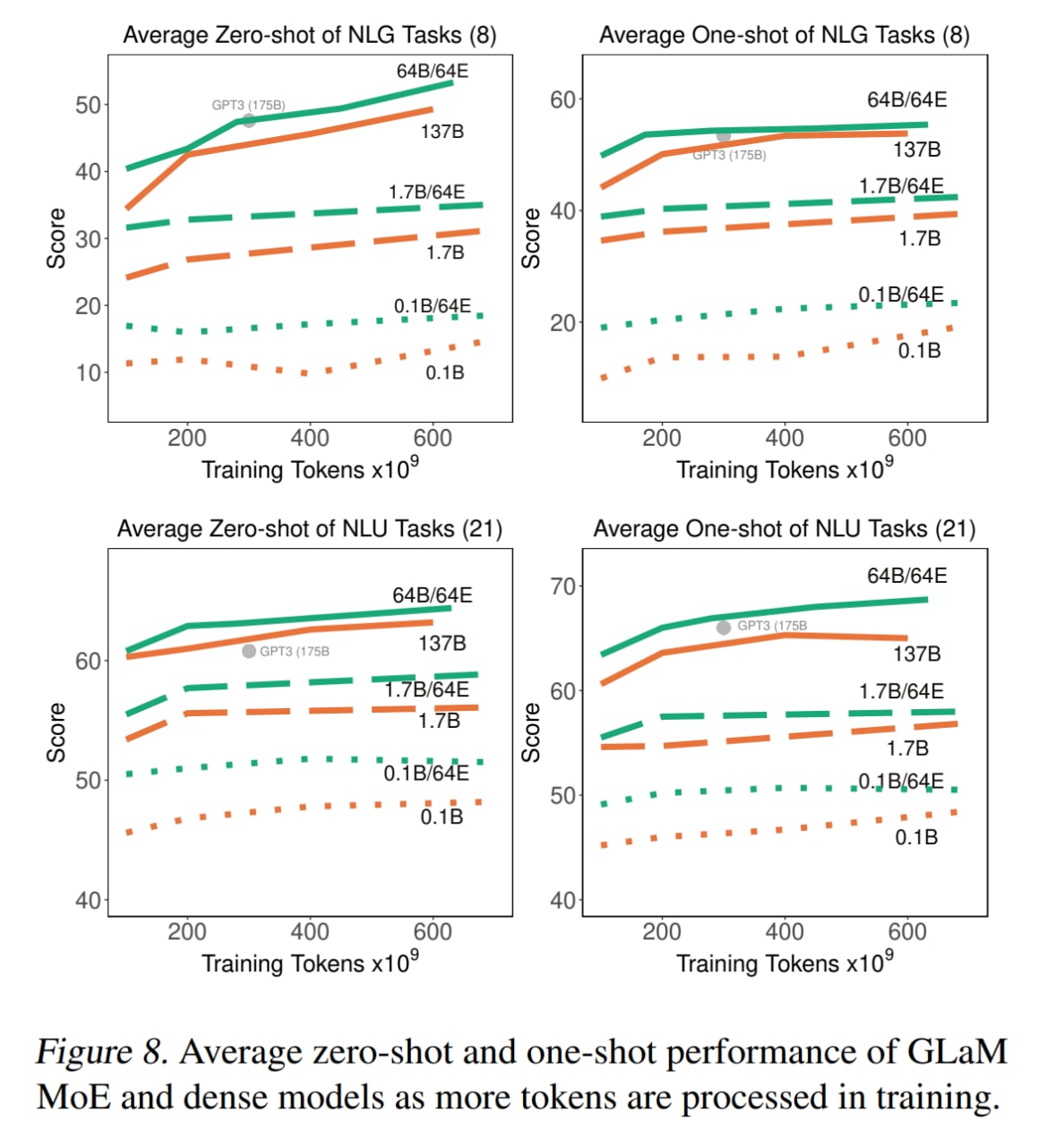
Во-первых, MoE оказываются более эффективны по данным — им требуется меньше данных, чем плотным моделям с сопоставимыми вычислительными требованиями, чтобы достичь сравнимого перформанса на zero-shot/one-shot.
Во-вторых, по количеству вычислений и потребляемой энергии MoE эффективнее плотных сетей. А если сравниваться с GPT-3, то самый большой GLaM потребовал примерно ⅓ энергии от обучения GPT-3.
Правда, тут же мы сравниваем обучение GPT-3 на GPU, которыми были V100, и GLaM на TPUv4, что сильно разное. По цифрам у железа вроде разница не безумная: у одного чипа TPUv3 было что-то в районе 120 TFLOPS/450 Вт, у TPUv4 грубо в районе 250 TFLOPS на фиг знает сколько ватт, возможно 450-500, у V100 было в районе 125 TFLOPS/300 Вт для тензорных ядер и FP16, у A100 было бы 312 TFLOPS/300-400 Вт. Тут конечно много дьявола в деталях, да и на пиковые значения плохо ориентироваться, но разница в железе кажется тоже должна была повлиять и не особо корректно всю разницу в потреблении приписывать архитектуре MoE.
Ещё из любопытных цифр на злобу дня — это carbon emissions. Полное обучение GLaM на 600B токенов оценено в 456 МВт*ч и 40.2 тонны выбросов CO2. Для GPT-3 приводятся цифры в 1297 МВт*ч (в другой таблице 1287, что кажется более правильно и соответствует другому источнику — https://arxiv.org/abs/2104.10350) и 552 тонны CO2. Для сравнения, в статье Паттерсона по упомянутой только что ссылке полёт целого самолёта в обе стороны SFO-JFK даёт в среднем 180.4 тонн. На этом фоне всё же и GPT-3 выглядела не так страшно (ну да, целых 3 таких полёта, что мне кажется несопоставимо с пользой модели), а GLaM так вообще круто.
Жаль вот только, модель не опубликована и будет ли как-то доступна, неясно.
Для оценки моделей отобрали 29 датасетов (8 для задач NLG, 21 для NLU). Это оригинальный набор из 42 датасетов, на котором оценивали GPT-3 (https://t.me/gonzo_ML/305), с отброшенными 7 синтетическими задачами на арифметику и т.п., а также 6 датасетами для машинного перевода. Сравнивают на zero-shot и one-shot.
Сравнивают разные модели с упором на одинаковое количество вычислений или количество активных параметров на токен.
В целом по 5 из 7 категорий задач GLaM заметно превзошла GPT-3. При этом GLaM 64B/64E (самая большая) с 96.6B активных весов на токен (у самой большой GPT-3 их 175B) во время инференса требует примерно в два раза меньше вычислений для того же входа.
На TriviaQA побили старую SoTA. На ANLI дают качество выше, чем у Megatron-NLG с 530B параметров, при этом требуя менее 20% вычислений последнего.
Авторы также поисследовали bias’ы модели, показали, что она установила SoTA на WinoGender, превзойдя GPT-3.
Отдельно померяли влияние качества данных, показали, что более качественные фильтрованные данные крайне важны, объёмом до этих цифр так просто не доберёшь.
И с ростом сети (и соответственно ростом размера отдельного эксперта), и с ростом числа экспертов, качество увеличивается.
По сравнению с dense моделями у MoE видны два преимущества.
Во-первых, MoE оказываются более эффективны по данным — им требуется меньше данных, чем плотным моделям с сопоставимыми вычислительными требованиями, чтобы достичь сравнимого перформанса на zero-shot/one-shot.
Во-вторых, по количеству вычислений и потребляемой энергии MoE эффективнее плотных сетей. А если сравниваться с GPT-3, то самый большой GLaM потребовал примерно ⅓ энергии от обучения GPT-3.
Правда, тут же мы сравниваем обучение GPT-3 на GPU, которыми были V100, и GLaM на TPUv4, что сильно разное. По цифрам у железа вроде разница не безумная: у одного чипа TPUv3 было что-то в районе 120 TFLOPS/450 Вт, у TPUv4 грубо в районе 250 TFLOPS на фиг знает сколько ватт, возможно 450-500, у V100 было в районе 125 TFLOPS/300 Вт для тензорных ядер и FP16, у A100 было бы 312 TFLOPS/300-400 Вт. Тут конечно много дьявола в деталях, да и на пиковые значения плохо ориентироваться, но разница в железе кажется тоже должна была повлиять и не особо корректно всю разницу в потреблении приписывать архитектуре MoE.
Ещё из любопытных цифр на злобу дня — это carbon emissions. Полное обучение GLaM на 600B токенов оценено в 456 МВт*ч и 40.2 тонны выбросов CO2. Для GPT-3 приводятся цифры в 1297 МВт*ч (в другой таблице 1287, что кажется более правильно и соответствует другому источнику — https://arxiv.org/abs/2104.10350) и 552 тонны CO2. Для сравнения, в статье Паттерсона по упомянутой только что ссылке полёт целого самолёта в обе стороны SFO-JFK даёт в среднем 180.4 тонн. На этом фоне всё же и GPT-3 выглядела не так страшно (ну да, целых 3 таких полёта, что мне кажется несопоставимо с пользой модели), а GLaM так вообще круто.
Жаль вот только, модель не опубликована и будет ли как-то доступна, неясно.