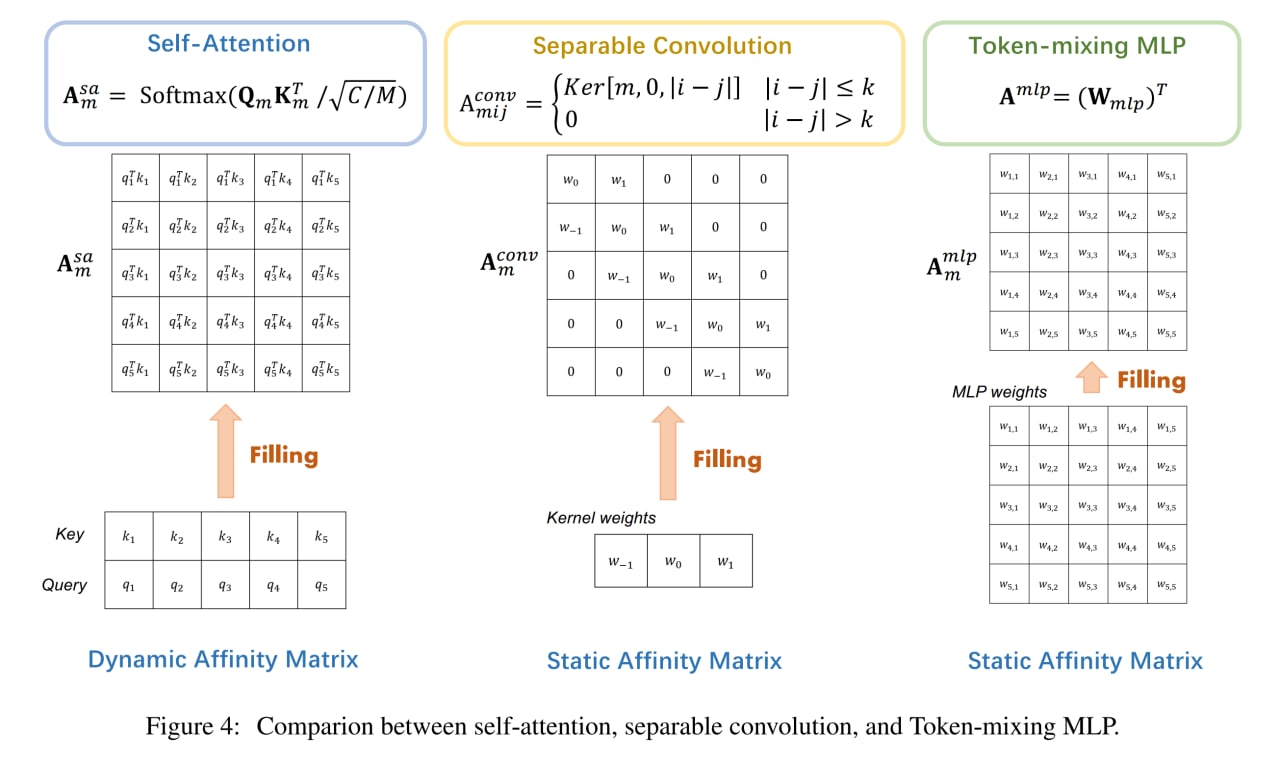
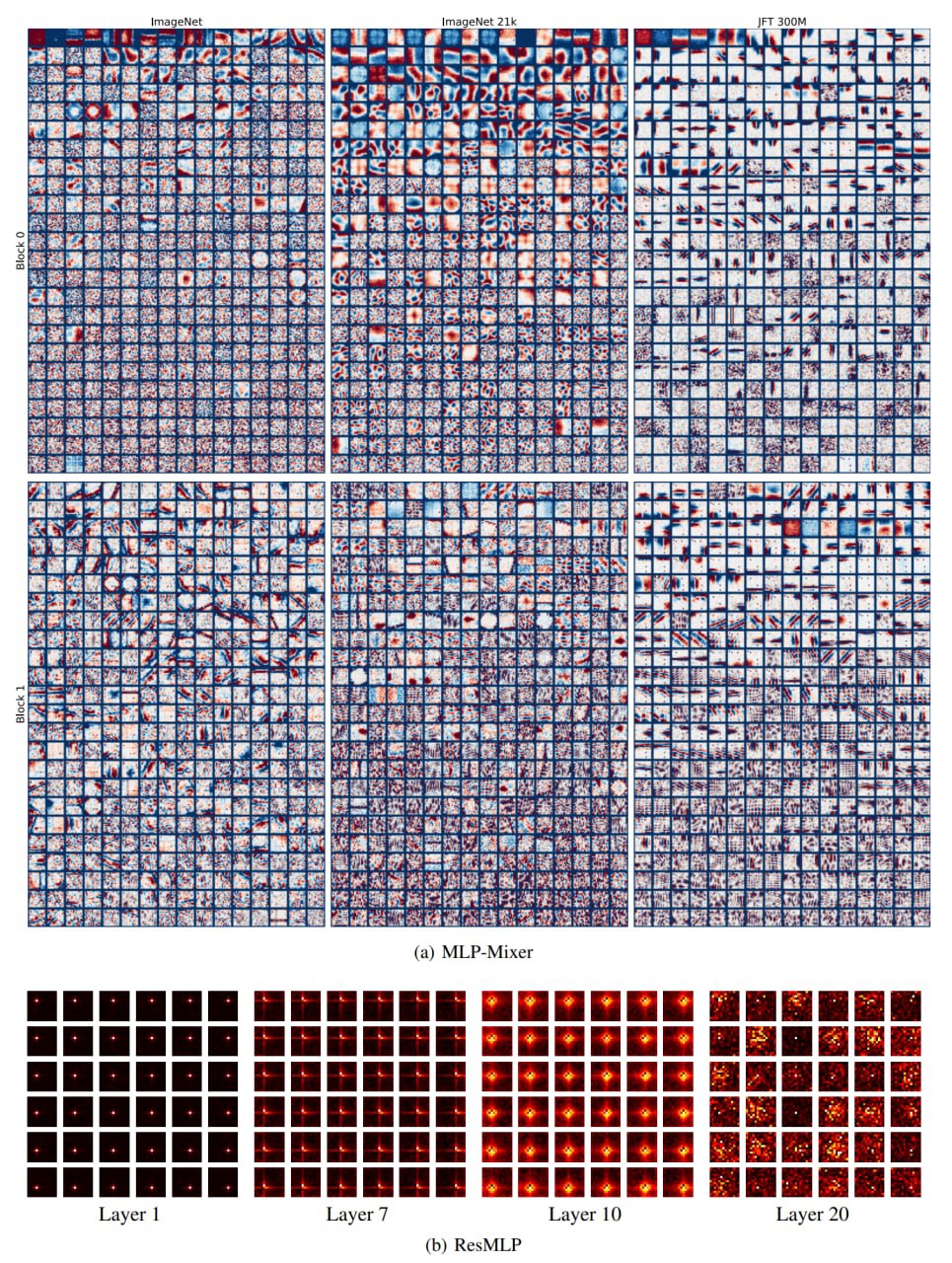
От свёрток MLP ощутимо отличается по локальности рецептивного поля. Полносвязные слои в итоге всё равно выучивают какие-то локальные фичи, это было видно и по MLP-Mixer, и по ResMLP, и по gMLP. Правда на более глубоких слоях MLP это обычно теряется (но может просто не хватает данных?). Также любопытно, что у двух очень похожих архитектур (MLP-Mixer и ResMLP) фичи получаются ощутимо разные, то есть это не какие-то универсальные визуальные фичи? Требует разбирательства.
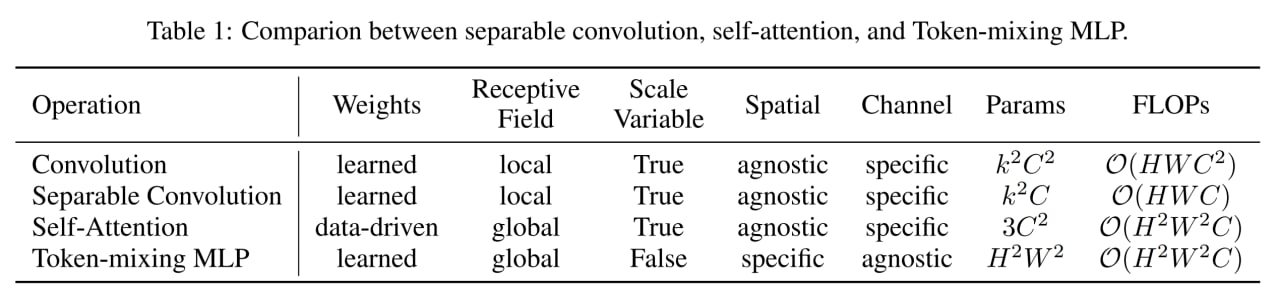
От трансформеров с весами, определяемыми данными, все остальные заметно отличаются тем, что у остальных веса выучиваются в процессе обучения и далее от данных не зависят (хотя, конечно, есть более продвинутые динамические свёртки, например, в знаковой работе “Pay Less Attention with Lightweight and Dynamic Convolutions” https://arxiv.org/abs/1901.10430).
При этом у MLP есть несколько боттлнеков.
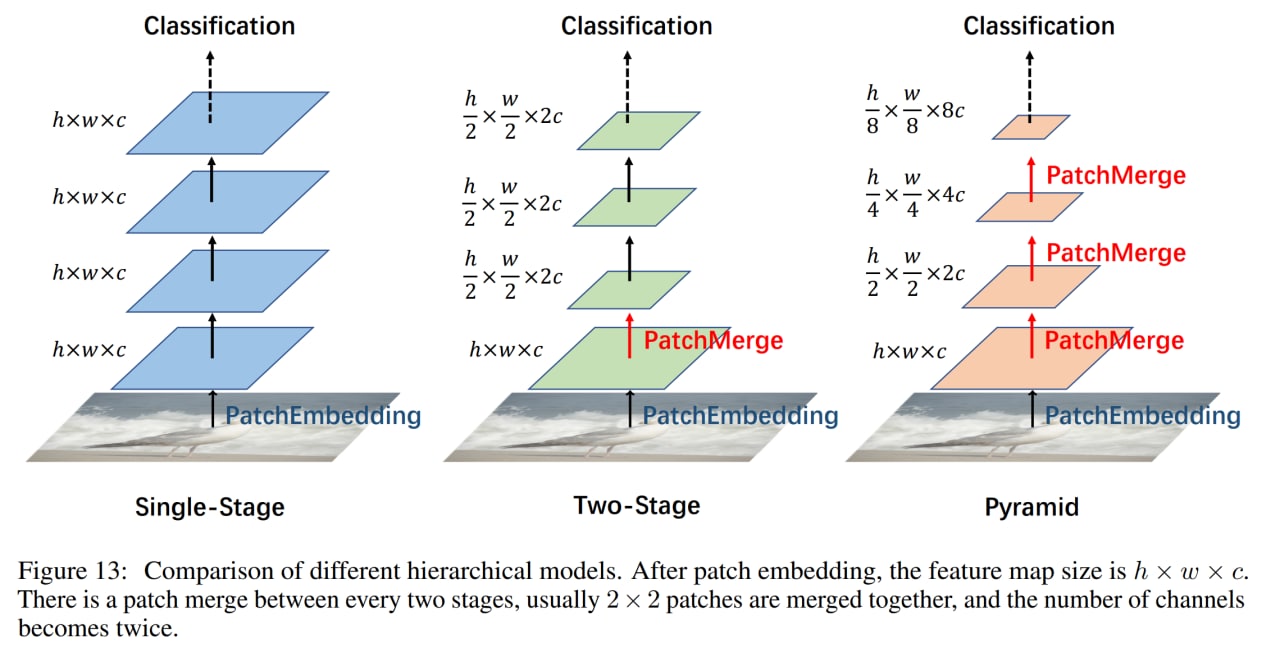
Первый очевидный — это переобучение, когда данных мало, так что надо готовить датасеты размера JFT-300M и больше. Второй — это вычислительная сложность, которая как и у стандартных трансформеров обычно квадратичная от размера входа (хотя MLP-Mixer вроде как военной смекалкой обходил это и был линейным). Третья проблема — заточенность MLP на конкретные входные разрешения, ибо размеры матриц весов полносвязных слоёв прошиты внутри и размерность входа в них обычно фигурирует. Ну и ещё одна потенциальная проблема в том, что в дефолтной композиции в виде пачки однотипных блоков, модель заточена на одно конкретное разрешение, а для некоторых задач хорошо бы иметь пирамиды фич (та же проблема есть и в дефолтном трансформере, поэтому там появились и рулят Swin Transformers и т.п.).
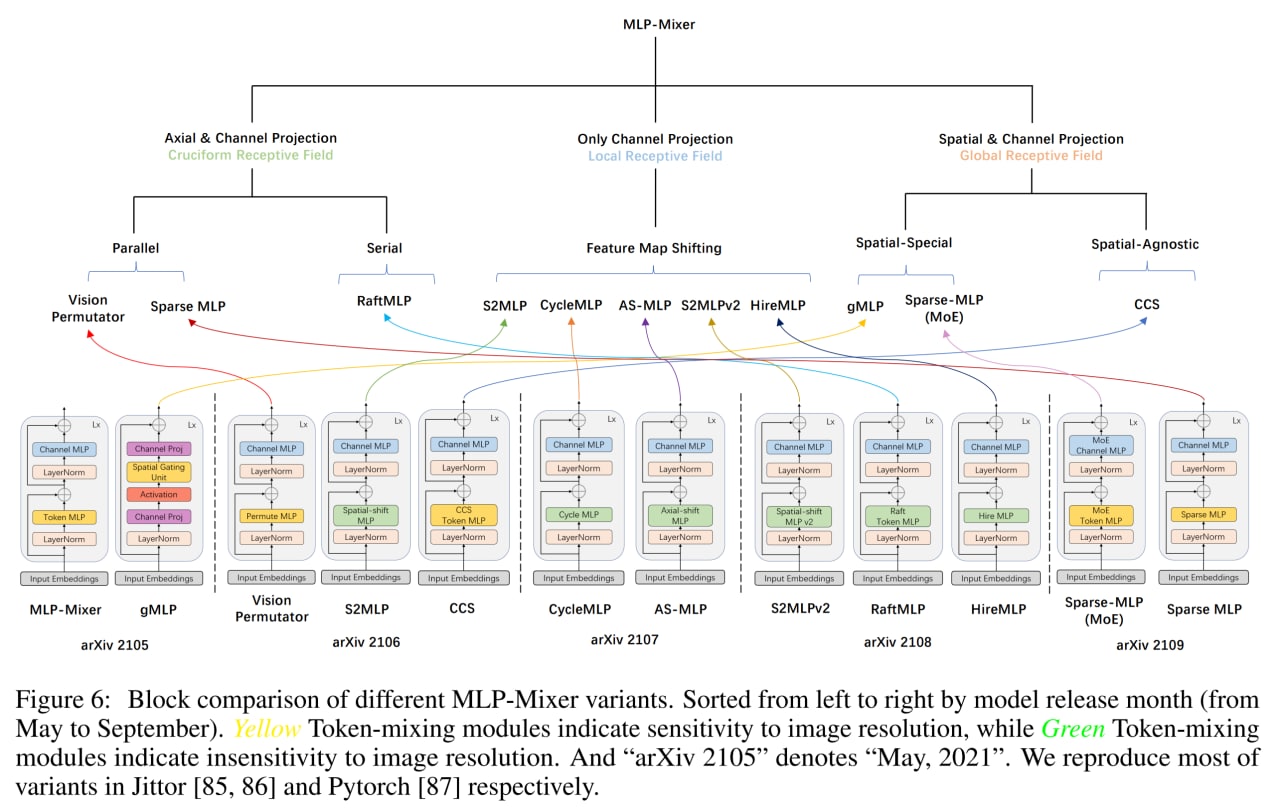
После MLP-Mixer и ко пошёл вал работ, устраняющих то или иное ограничение. Если посмотреть на Fig.6 из работы, то видно, что всё это так или иначе вариации на тему со сходной структурой и все кроме gMLP содержат тандем spatial MLP и channel MLP. Значимая часть улучшений при этом фокусируется на spatial MLP, чтобы сделать его нечувствительным к разрешению. Прям генеалогию можно простраивать, а если мы ещё придём к кодированию структуры всех сетей через какой-то универсальный язык (aka геном), то прям и биоинформатические методы можно было бы сюда применить.
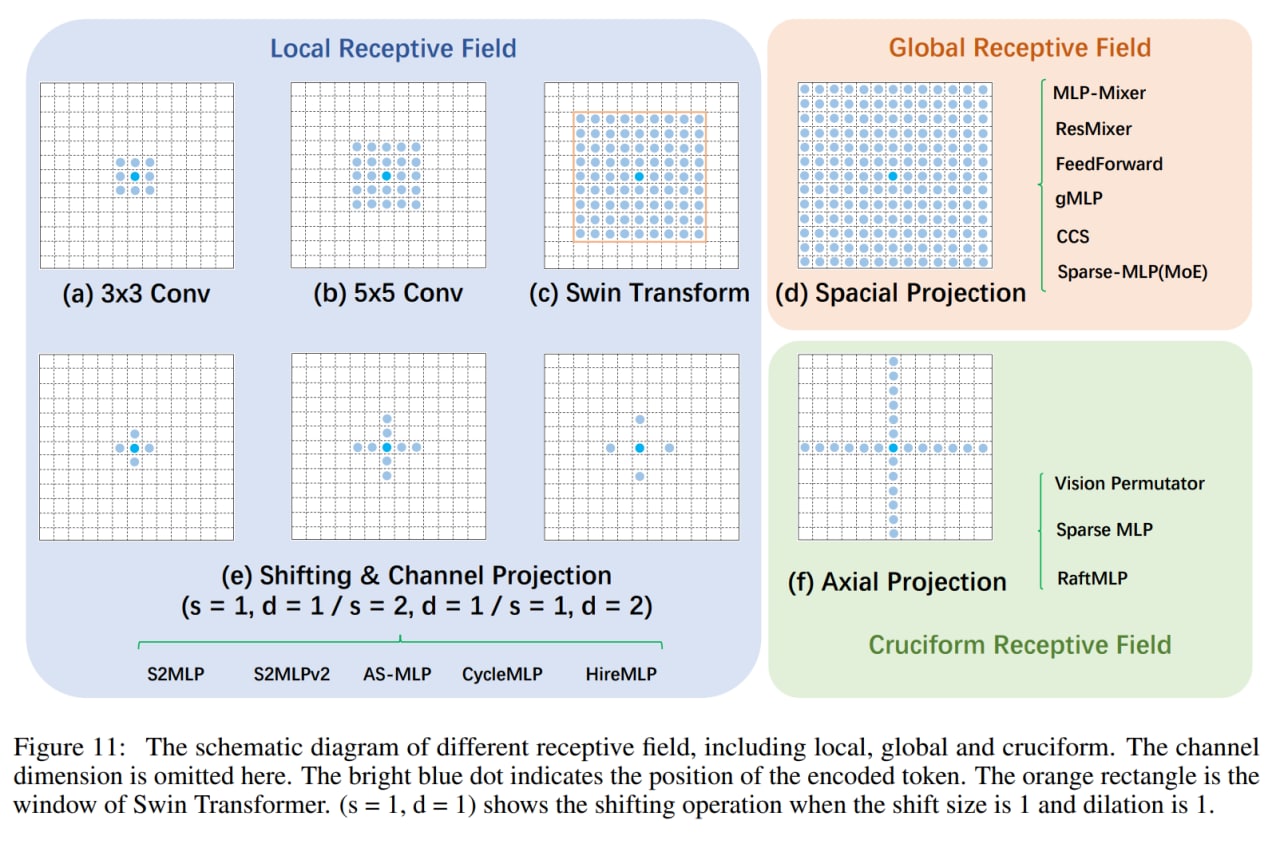
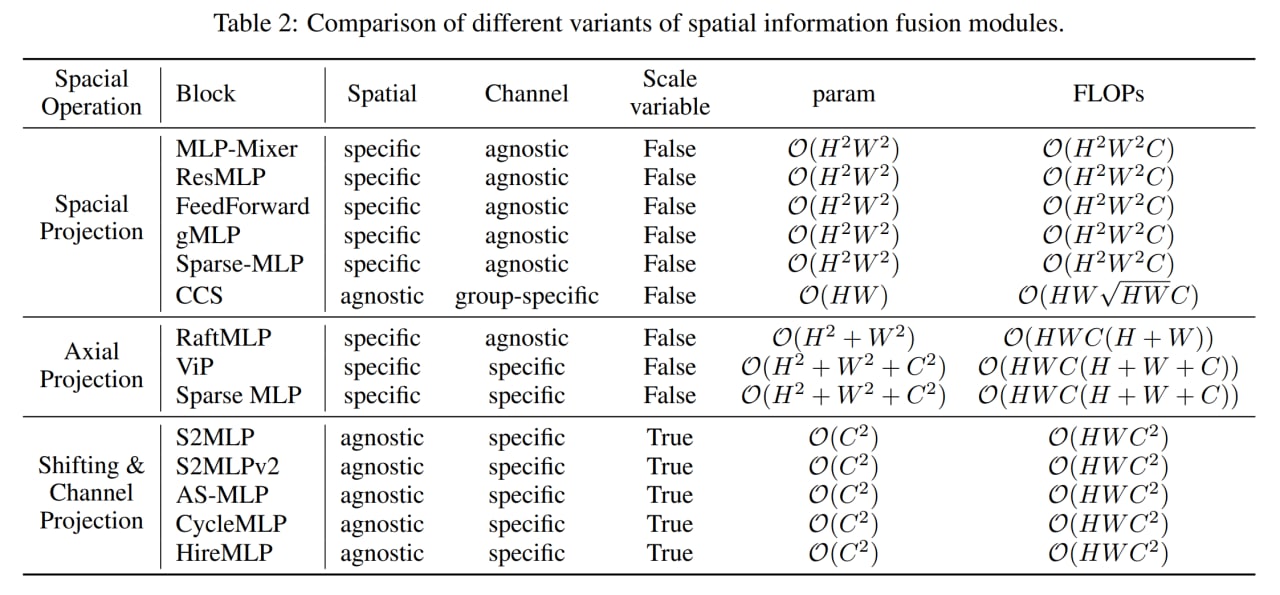
Авторы поделили все варианты на три большие группы. Группа 1 содержит полные пространственные и канальные маппинги, группа 2 содержит аксиальные маппинги по пространственным измерениям плюс канальные, и группа 3 только канальные маппинги.
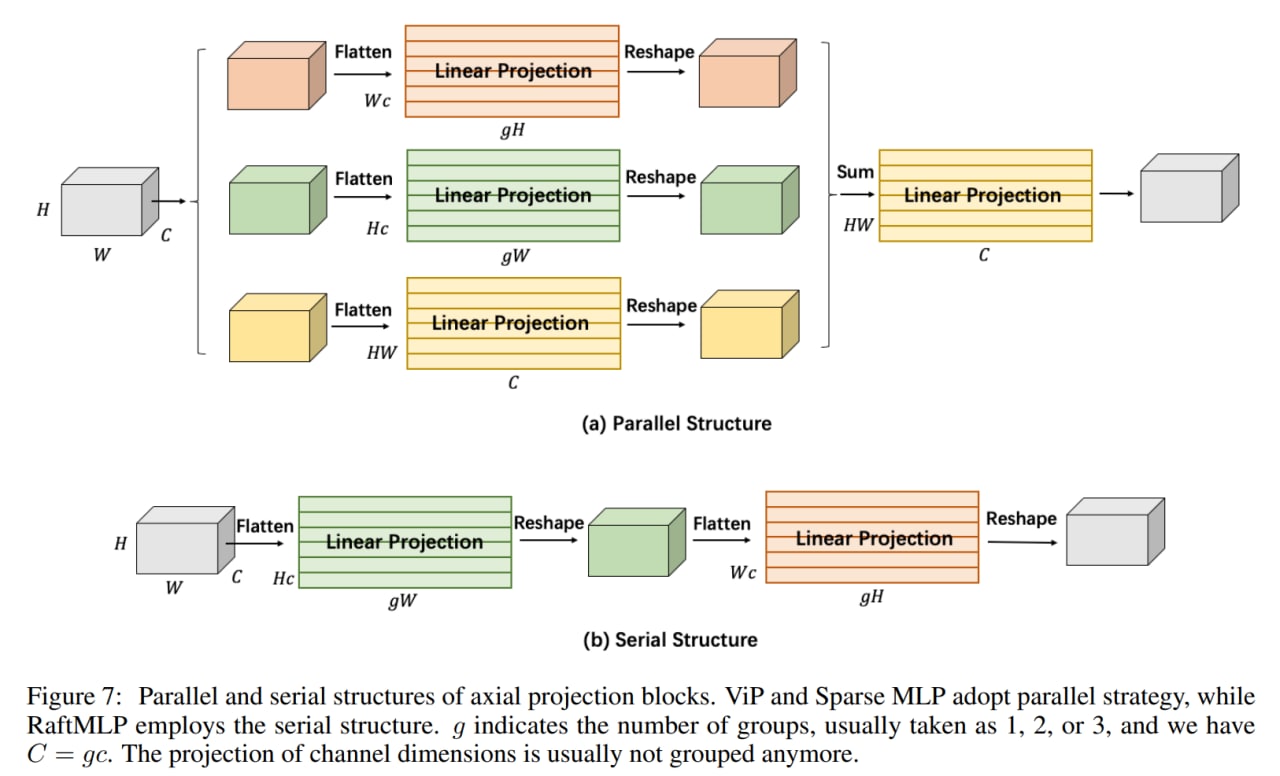
Аксиальные маппинги — это оптимизация обычных полных, чтобы иметь меньше параметров, но при этом всё равно захватывать осмысленные дальние взаимодействия, только теперь они должны быть строго по вертикальной и горизонтальной осям, что конечно уменьшает выразительность (в работе есть пример картинки со вратарём в прыжке за мячом, где мяч в стороне по диагонали и такое бы не поймалось), но возможно всё равно good enough. Vision Permutator (ViP) — пример такой модели, в его Permute-MLP три параллельные ветви: для горизонтальных, вертикальных и канальных проекций. В Sparse MLP аналогично. В RaftMLP горизонтальная и вертикальная ветви работают последовательно.
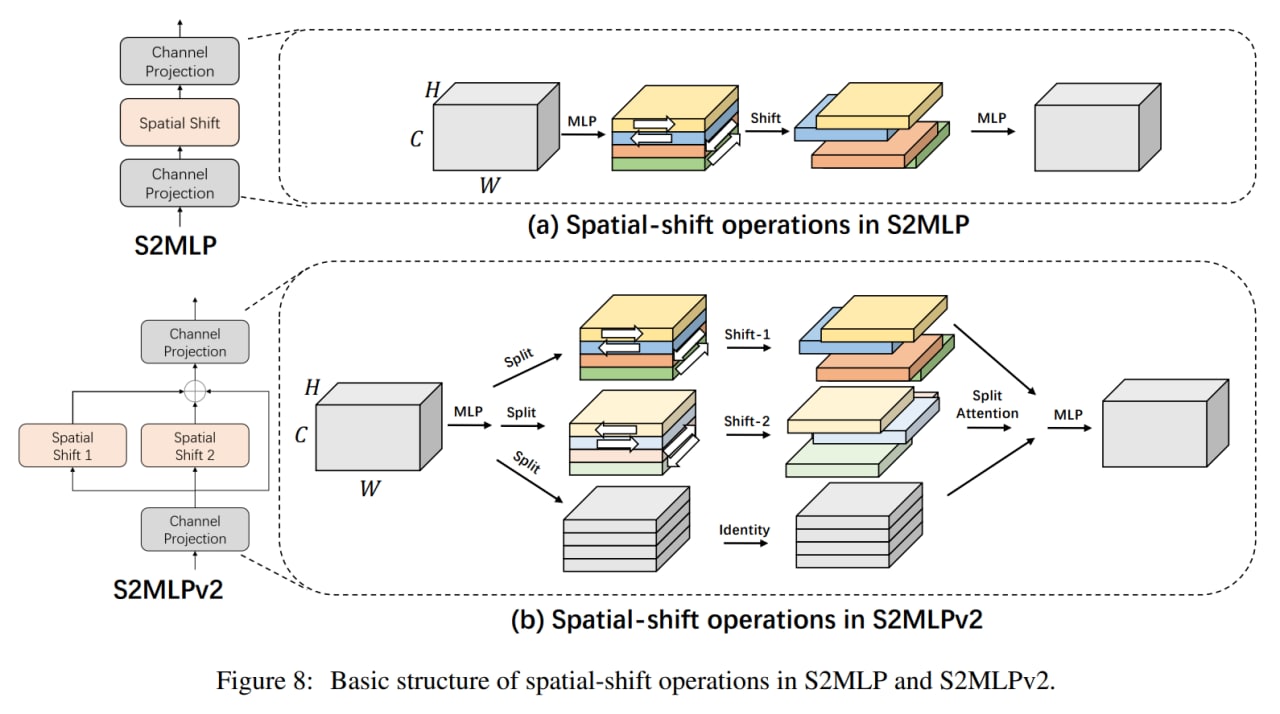
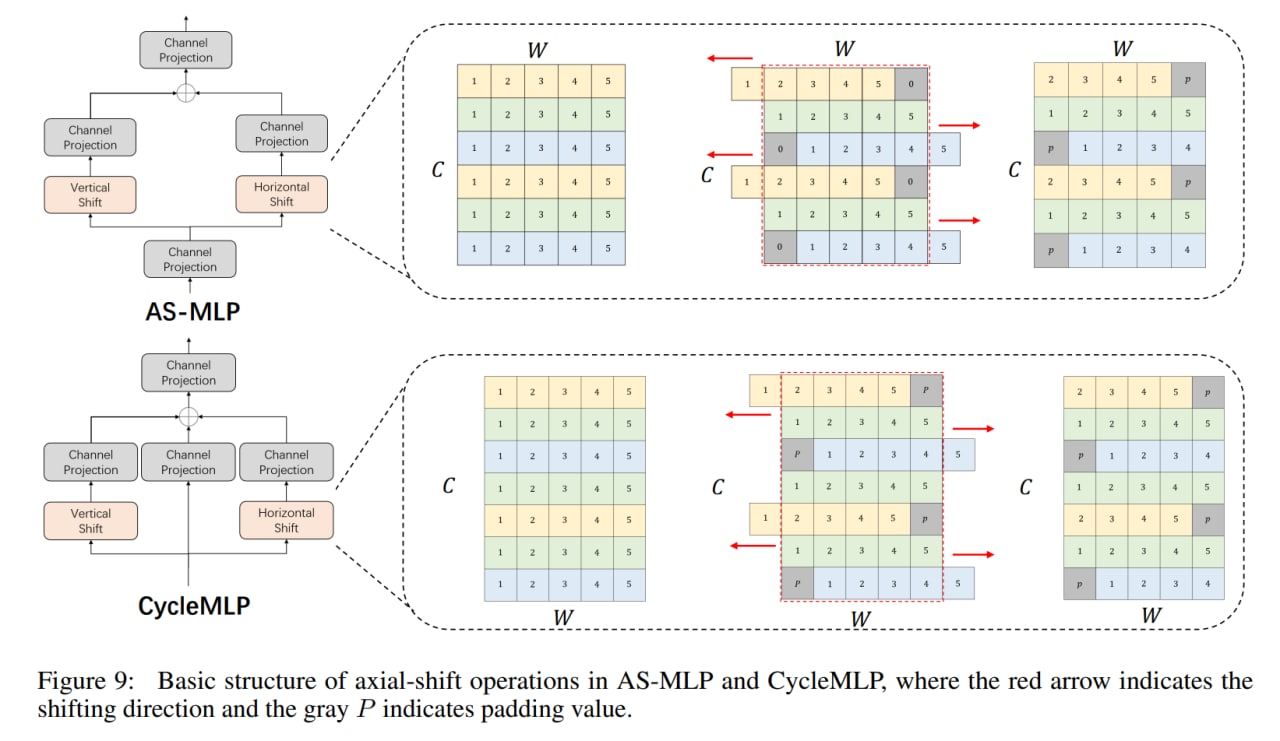
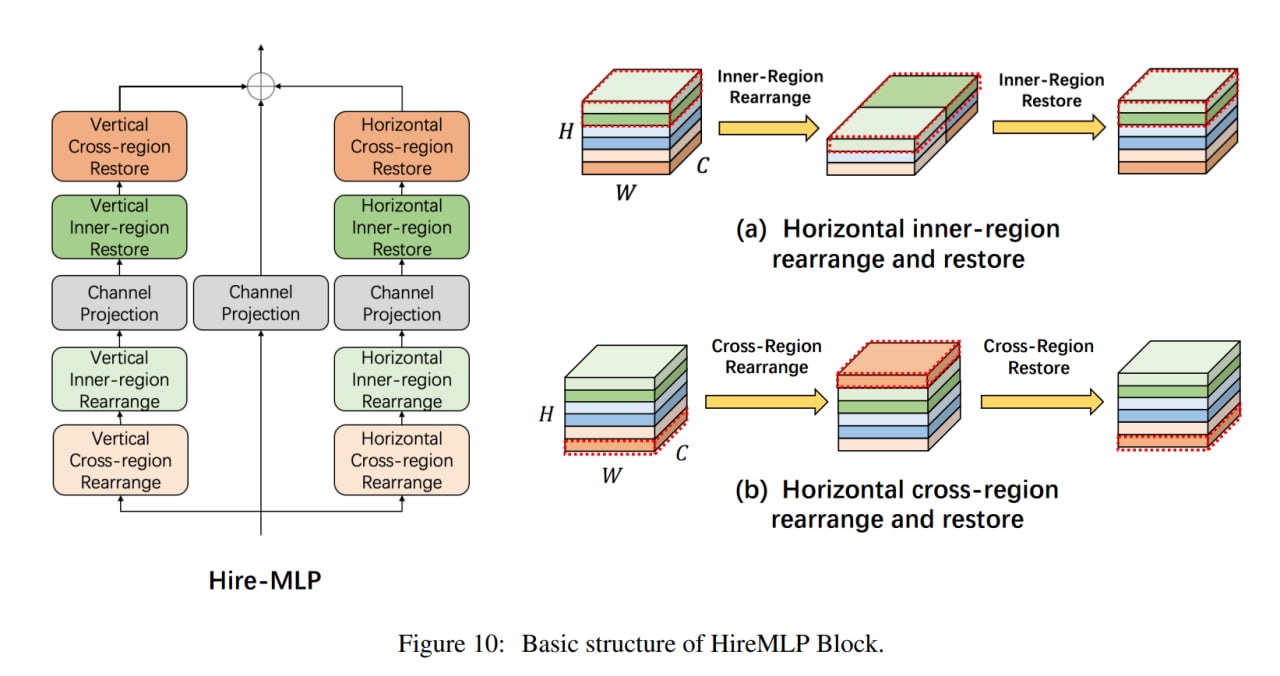
Модели на основе только проекций каналов заменяют пространственные полносвязные слои на канальные проекции (или свёртки 1x1), что приводит к тому, что патчи более не взаимодействуют между собой и они для восстановления рецептивного поля прибегают к различным сдвигам или перемещениям карт фич, чтобы у разных позиций была возможность взаимодействовать через канальное измерение. Выглядит, честно говоря, как “купи козу” - “продай козу”. Среди таких моделей S2MLP, S2MLPv2, AS-MLP (Axial Shifted) или Cycle MLP (эти прибегают к deformable convolution). Только HireMLP предлагает что-то ощутимо новое по сравнению с соседями, используя inner-region rearrangements (разбивают карты фич на группы и группируют вдоль пространственных измерений, это даёт локальные взаимодействия) и cross-region rearrangements (сдвигают токены в каком-то направлении на заданный шаг, это даёт более глобальные взаимодействия). Ещё есть ConvMLP, но он так вообще скорее CNN.
От трансформеров с весами, определяемыми данными, все остальные заметно отличаются тем, что у остальных веса выучиваются в процессе обучения и далее от данных не зависят (хотя, конечно, есть более продвинутые динамические свёртки, например, в знаковой работе “Pay Less Attention with Lightweight and Dynamic Convolutions” https://arxiv.org/abs/1901.10430).
При этом у MLP есть несколько боттлнеков.
Первый очевидный — это переобучение, когда данных мало, так что надо готовить датасеты размера JFT-300M и больше. Второй — это вычислительная сложность, которая как и у стандартных трансформеров обычно квадратичная от размера входа (хотя MLP-Mixer вроде как военной смекалкой обходил это и был линейным). Третья проблема — заточенность MLP на конкретные входные разрешения, ибо размеры матриц весов полносвязных слоёв прошиты внутри и размерность входа в них обычно фигурирует. Ну и ещё одна потенциальная проблема в том, что в дефолтной композиции в виде пачки однотипных блоков, модель заточена на одно конкретное разрешение, а для некоторых задач хорошо бы иметь пирамиды фич (та же проблема есть и в дефолтном трансформере, поэтому там появились и рулят Swin Transformers и т.п.).
После MLP-Mixer и ко пошёл вал работ, устраняющих то или иное ограничение. Если посмотреть на Fig.6 из работы, то видно, что всё это так или иначе вариации на тему со сходной структурой и все кроме gMLP содержат тандем spatial MLP и channel MLP. Значимая часть улучшений при этом фокусируется на spatial MLP, чтобы сделать его нечувствительным к разрешению. Прям генеалогию можно простраивать, а если мы ещё придём к кодированию структуры всех сетей через какой-то универсальный язык (aka геном), то прям и биоинформатические методы можно было бы сюда применить.
Авторы поделили все варианты на три большие группы. Группа 1 содержит полные пространственные и канальные маппинги, группа 2 содержит аксиальные маппинги по пространственным измерениям плюс канальные, и группа 3 только канальные маппинги.
Аксиальные маппинги — это оптимизация обычных полных, чтобы иметь меньше параметров, но при этом всё равно захватывать осмысленные дальние взаимодействия, только теперь они должны быть строго по вертикальной и горизонтальной осям, что конечно уменьшает выразительность (в работе есть пример картинки со вратарём в прыжке за мячом, где мяч в стороне по диагонали и такое бы не поймалось), но возможно всё равно good enough. Vision Permutator (ViP) — пример такой модели, в его Permute-MLP три параллельные ветви: для горизонтальных, вертикальных и канальных проекций. В Sparse MLP аналогично. В RaftMLP горизонтальная и вертикальная ветви работают последовательно.
Модели на основе только проекций каналов заменяют пространственные полносвязные слои на канальные проекции (или свёртки 1x1), что приводит к тому, что патчи более не взаимодействуют между собой и они для восстановления рецептивного поля прибегают к различным сдвигам или перемещениям карт фич, чтобы у разных позиций была возможность взаимодействовать через канальное измерение. Выглядит, честно говоря, как “купи козу” - “продай козу”. Среди таких моделей S2MLP, S2MLPv2, AS-MLP (Axial Shifted) или Cycle MLP (эти прибегают к deformable convolution). Только HireMLP предлагает что-то ощутимо новое по сравнению с соседями, используя inner-region rearrangements (разбивают карты фич на группы и группируют вдоль пространственных измерений, это даёт локальные взаимодействия) и cross-region rearrangements (сдвигают токены в каком-то направлении на заданный шаг, это даёт более глобальные взаимодействия). Ещё есть ConvMLP, но он так вообще скорее CNN.