Size: a a a
2019 November 06

2019 November 07

Follow the thread
2019 November 08


Переслано от viktor


2019 November 09
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
Zhang et al. [Microsoft]
arxiv.org/abs/1911.00536
GPT2 + Dialogue data = DialoGPT
Trained on Reddit data (not a very big dataset, about 2Gb). Code and the model are released.
Zhang et al. [Microsoft]
arxiv.org/abs/1911.00536
GPT2 + Dialogue data = DialoGPT
Trained on Reddit data (not a very big dataset, about 2Gb). Code and the model are released.

Unsupervised Cross-lingual Representation Learning at Scale
Conneau et al. [FAIR]
arxiv.org/abs/1911.02116
TL;DR based on FAIR blog post
Building on the cross-lingual approach that we used with XLM and RoBERTa, we increased the number of languages and training examples for our new model, training self-supervised cross-lingual representations from more than two terabytes of publicly available CommonCrawl data that had been cleaned and filtered. This included generating new unlabeled corpora for low-resource languages, scaling the amount of training data available for those languages by two orders of magnitude.
During fine-tuning, we leveraged the ability of multilingual models to use labeled data in multiple languages in order to improve downstream task performance. This enabled our model to achieve state-of-the-art results on cross-lingual benchmarks while exceeding the per-language performance of monolingual BERT models.
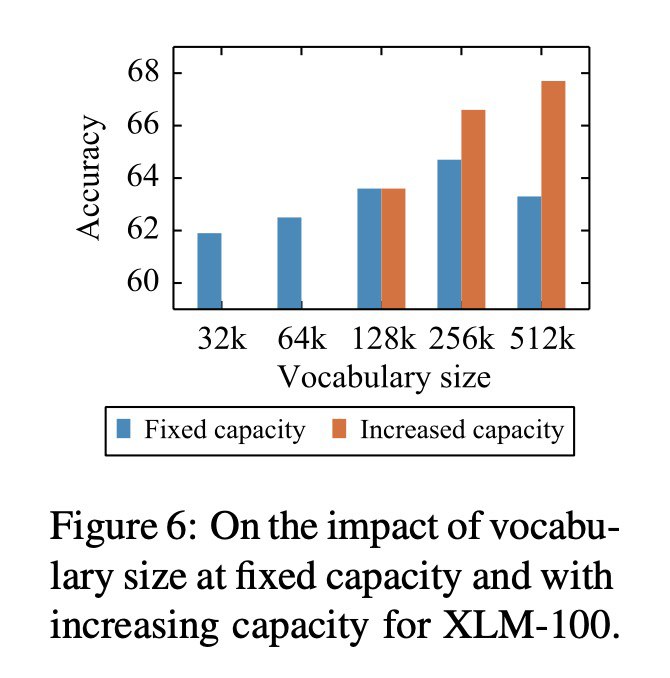
We tuned our model’s parameters to offset the fact that using cross-lingual transfer to scale models to more languages also limits the model’s capacity to understand each of those languages. Our parameter changes included upsampling low-resource languages during training and vocabulary construction, generating a larger shared vocabulary, and increasing the overall model capacity up to 550 million parameters.
Conneau et al. [FAIR]
arxiv.org/abs/1911.02116
TL;DR based on FAIR blog post
Building on the cross-lingual approach that we used with XLM and RoBERTa, we increased the number of languages and training examples for our new model, training self-supervised cross-lingual representations from more than two terabytes of publicly available CommonCrawl data that had been cleaned and filtered. This included generating new unlabeled corpora for low-resource languages, scaling the amount of training data available for those languages by two orders of magnitude.
During fine-tuning, we leveraged the ability of multilingual models to use labeled data in multiple languages in order to improve downstream task performance. This enabled our model to achieve state-of-the-art results on cross-lingual benchmarks while exceeding the per-language performance of monolingual BERT models.
We tuned our model’s parameters to offset the fact that using cross-lingual transfer to scale models to more languages also limits the model’s capacity to understand each of those languages. Our parameter changes included upsampling low-resource languages during training and vocabulary construction, generating a larger shared vocabulary, and increasing the overall model capacity up to 550 million parameters.