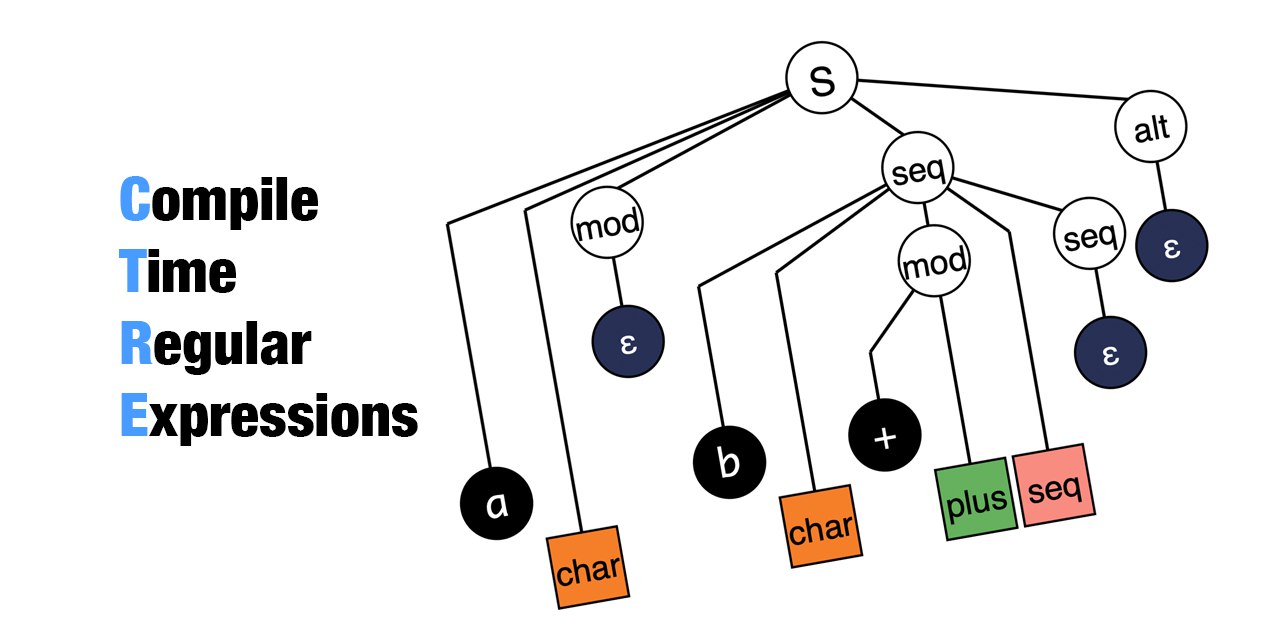
#prog #моё
Если вы используете регулярные выражения — вам должно быть за это стыдноУ регулярных выражений есть куча недостатков, и, на мой взгляд, их слишком часто используют там, где не надо. Сейчас я расскажу о том, что же с ними не так.
Проблемы1. Регулярные выражения (за некоторыми исключениями -
1,
2) парсятся в рантайме.
В подавляющем большинстве случаев строка, используемая для построения регулярных выражений, является константной, поэтому принципиально ничего не мешает провести компиляцию регулярного выражения одновременно с компиляцией программы. Большая часть моих следующих претензий напрямую вытекает из этого свойства.
2. Регулярные выражения (
далее RE) фактически динамически типизированы.
Разберу подробнее:
2.а. Если в описании RE есть ошибка (незакрытая скобка, обратная ссылка на несуществующий паттерн) — ты не узнаешь об этом до запуска программы. Если RE находится в функции, которая редко вызывается и которую не покрывают тесты, то баг может всплыть уже в, казалось бы, сто лет нормально работающей программе.
2.б. В качестве аргумента для RE используется строка — слабо структурированный тип данных. Какой бы сложной не была бы структура, заданная RE, в статически типизированном языке приходится возвращать значение одного и того же типа, поэтому вся информация о структуре теряется.
Хочешь достать текст из некой группы захвата? Вот тебе геттеры по индексам — разумеется, все возвращают Option, даже если данная группа заведомо присутствует. Ах да, не забудь на всякий случай их все проверить и поменять, где надо, когда поменяешь RE.
Что, вы говорите, именованные группы захвата? Ну, окей, именованные. Ну, геттеры по строкам, а не по индексам. Но геттеры всё равно отдают Option, а теперь у тебя появилась невероятная возможность опечататься в геттере. Конечно, можно использовать строковые константы, но, во-первых, Option никуда не денутся, а во-вторых, эти же константы по-хорошему надо использовать для строки, из которой создаётся RE, так что вместо просто литерала будет конкатенация нескольких строк. Ура, читаемость!
2.в. Хочешь, чтобы IDE ловила ошибки? А вот хрен тебе: если только у тебя RE не
встроены в язык, тебе IDE ничего не подскажет, ибо для неё это всего лишь строка, не отличающаяся от всех прочих.
2.г. Хочешь быстрые RE? Надейся, что автор используемой тобой библиотеки смог написать хороший компилятор RE. Что, говоришь, у твоего ЯП есть оптимизирующий компилятор? Очень хорошо, да только он тут не поможет и не может помочь, потому что он ничего про конкретное RE не знает.
3. Такой вещи, как "просто регулярное выражение", не существует.
Есть Perl RE (и
PCRE),
POSIX RE (и не одна разновидность), и есть... Библиотеки, которые реализуют один из этих стандартов.
Или не реализуют.
Или реализуют не полностью.
Или реализуют с отличиями.
Или просто бажные.
А есть ещё жадное и нежадное сопоставление. Движок для RE, который ты используешь, точно умеет в оба варианта? А какой использует по умолчанию?
Короче, практически любое нетривиальное RE, вероятно, непереносимо между разными языками и разными библиотеками одного и того же языка.
4. У RE просто отвратительная композируемость. Не, ну серьёзно.
Тебе нужно сматчить подряд два RE или одно, но несколько раз? Делай сам. Руками. Ты ж программист, писать программы — это твоя обязанность.
Хочешь протестировать отдельно кусок сложного RE? Не вопрос, компилируй отдельно подстроку. Да, компилируй заново. Ну и что, что там структура одинаковая? А почему одинаковая, собственно? Ты разве синхронно меняешь строки привнесении изменений? Да, да, можно конкатенировать строки. Да, так структура у этих кусочков будет одинаковая. Нет, ты не можешь этим воспользоваться.
Что, говоришь, у тебя структура текста параметризована некоторым значением? Нет, ты не можешь сделать RE с аргументом. Ручками вклеивай значение и компилируй каждый раз отдельно. Да, и кеш у
JIT-компилятора RE не забудь инвалидировать полностью.
Что ты там говоришь про декомпозицию? Да не ссы, пиши всё в одну большую строку. Деды, вон, в одном файле всё писали — и ничего, выжили. Они терпели — и ты потерпи.