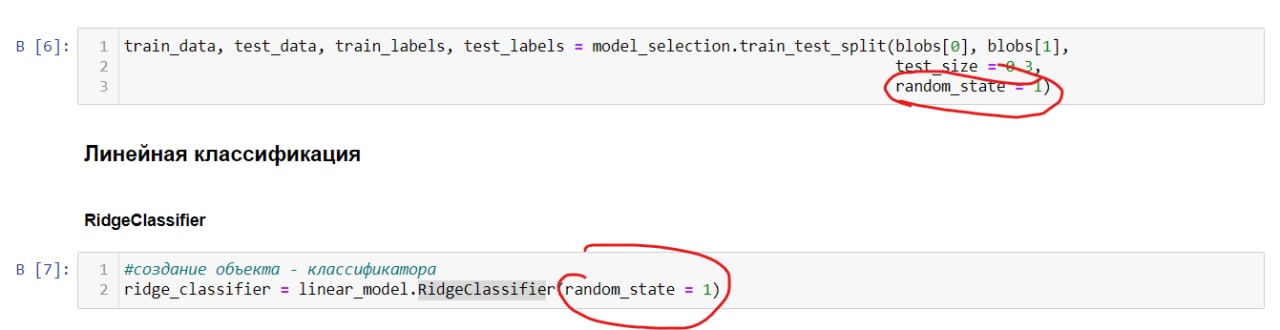
Здравствуйте! На второй неделе курса "Обучение на размеченных данных" сначала рассматривается сплит данных на train и на test с параметром random_state=1, а далее уже при создании модели классификатора в линейный классификатор тоже подставляется этот параметр (random_state=1). Но на примерах с линейной регрессией данный параметр не учитывается ни в разбиении на train и test, ни в параметрах создания модели регрессии. Помогите, пожалуйста, понять, когда необходимо использовать данный параметр, а когда нет.