e
Переслано от Renarde
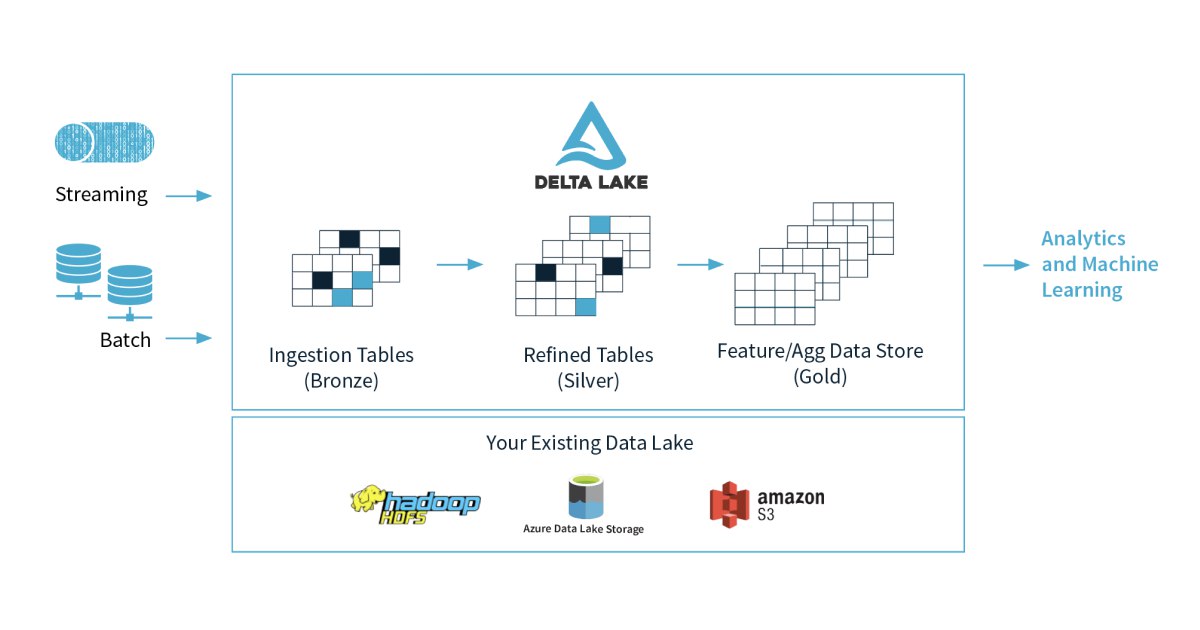
есть логическая разница между data lake / delta lake.
вкратце - data lake обычно - это append-only хранилище для данных в их исходном формате (приходит JSON из источника - храним JSON, приходит Avro - храним Avro). Физически это просто набор бакетов в S3-like системе, внутри которых лежат данные с источника.
Дальше обычно на данных из лейка собирают отдельные витрины и отгружают их куда-нибудь в аналитическое хранилище.
Это работающий подход, и много кто так делает, но у него есть минусы, например:
1. перевычитка сырых данных для ML может быть долгой/неэффективной
2. GDPR-related проблемы (удаление данных по where условию)
3. изменение схемы данных (актуально когда данные льются из микросервисов и внутри организации нет контрактов между дев-командами и дата-командами)
4. Мелкие технические проблемы - msck repair table, small files problem
Delta Lake собственно и нацелен решать такие проблемы за счет нового OSS формата, который называется delta . Идея в следующем - мы продолжаем хранить данные в S3-like FS, но к этому добавляется новый функционал:
1. MERGE (UPSERT) / DELETE - возможность обновлять и/или удалять данные по where условию, например - ключу
2. time travel - возможность откатить версию таблицы (или просто прочитать version as of от какой-то даты или timestamp)
3. schema evolution для таблиц
4. OPTIMIZE решает проблему маленьких файлов
5. Таблицы допускают concurrent writes / concurrent reads в т.ч. в стримах
6. Удобное API для стриминга, включая возможности читать с заданной версии / таймстампа
Важно заметить что:
- часть озвученного функционала есть только внутри Databricks
- есть и другие файловые форматы которые похожи по смыслу, самые популярные - Hudi и Iceberg. Вот тут и тут сравнения.
Про то, каким образом устроена дельта и дельта лог можно почитать вот эту статью с VLDB.
вкратце - data lake обычно - это append-only хранилище для данных в их исходном формате (приходит JSON из источника - храним JSON, приходит Avro - храним Avro). Физически это просто набор бакетов в S3-like системе, внутри которых лежат данные с источника.
Дальше обычно на данных из лейка собирают отдельные витрины и отгружают их куда-нибудь в аналитическое хранилище.
Это работающий подход, и много кто так делает, но у него есть минусы, например:
1. перевычитка сырых данных для ML может быть долгой/неэффективной
2. GDPR-related проблемы (удаление данных по where условию)
3. изменение схемы данных (актуально когда данные льются из микросервисов и внутри организации нет контрактов между дев-командами и дата-командами)
4. Мелкие технические проблемы - msck repair table, small files problem
Delta Lake собственно и нацелен решать такие проблемы за счет нового OSS формата, который называется delta . Идея в следующем - мы продолжаем хранить данные в S3-like FS, но к этому добавляется новый функционал:
1. MERGE (UPSERT) / DELETE - возможность обновлять и/или удалять данные по where условию, например - ключу
2. time travel - возможность откатить версию таблицы (или просто прочитать version as of от какой-то даты или timestamp)
3. schema evolution для таблиц
4. OPTIMIZE решает проблему маленьких файлов
5. Таблицы допускают concurrent writes / concurrent reads в т.ч. в стримах
6. Удобное API для стриминга, включая возможности читать с заданной версии / таймстампа
Важно заметить что:
- часть озвученного функционала есть только внутри Databricks
- есть и другие файловые форматы которые похожи по смыслу, самые популярные - Hudi и Iceberg. Вот тут и тут сравнения.
Про то, каким образом устроена дельта и дельта лог можно почитать вот эту статью с VLDB.