Алексей Лукацкий проверил регуляторные документы по инфобезу через наш сервис Простой язык [1] и отметил наиболее сложную нормативку. А я со своей стороны расскажу что когда-то простой русский язык я сделал после того как потратил несколько месяцев на то чтобы адаптировать формулы английского языка под русский. Это было непросто и делал я это, Вы не поверите, брут-форсным перебором нескольких миллионов комбинаций коэффициентов.
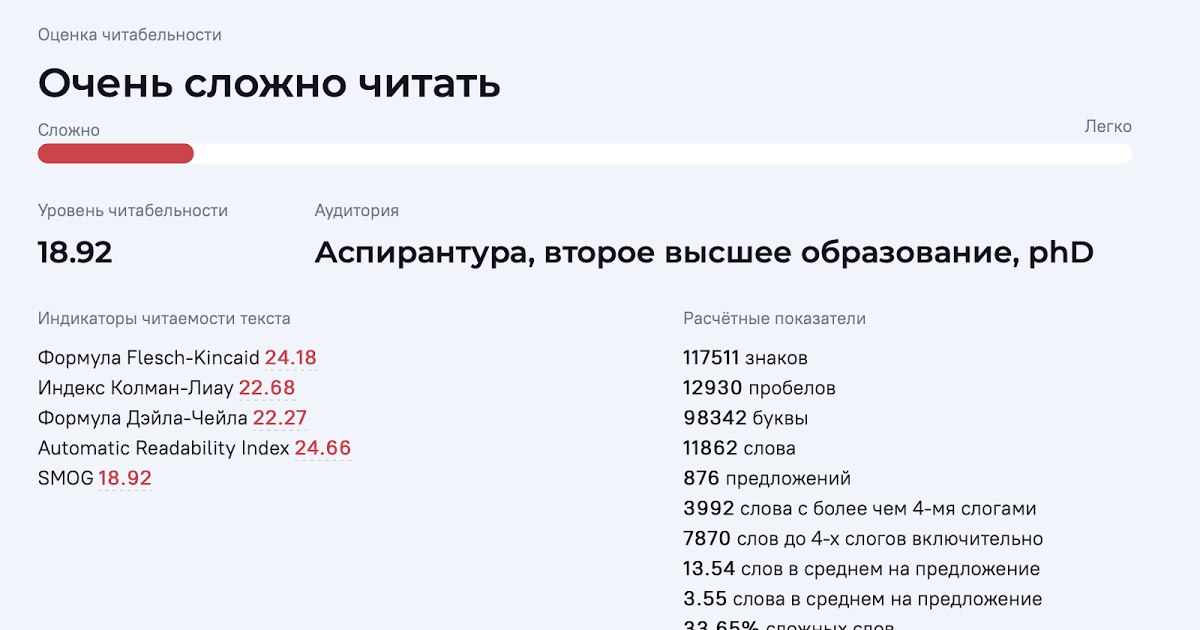
Потому что самое главное в этих формулах - это привязка значений к годам обучения. Если формула выдаёт 10 - это означает что 10 лет надо учиться чтобы понять этот текст (примерно 9-11 классы школы), а сложность в 18 означает что учиться надо 18 лет (а то есть 11 классов школы + 5 лет ВУЗа + ещё чему-то, например, в аспирантуре) ну и так далее.
Дело в том что формулы читабельности основаны на нескольких параметрах сложности текста таких как:
- среднее число слов на предложение
- среднее число слогов в словах
- среднее число слогов на предложение
- число сложных слов на предложение
и так далее.
Есть корреляция между сложностью текста и этими и другими параметрами, но как эту корреляцию переложить в формулу? И вот для этого я собирал кучу текстов для внеклассного чтения где были рекомендации для возраста и адаптировал формулы под поиск
наименьшего среднего отклонения и
наименьшего максимального отклонения. Иначе говоря, если если коэффициенты у формулы должны давать результат при котором максимально допустимое отклонение в оценки сложности текста не более 2, то есть если текст для внеклассного чтения для 9-го класса то алгоритм не может ошибаться в его отношении в пределах 9-11, но не более. А среднее отклонение по всей обучающей выборке должно быть как можно ниже.
Дальше чтобы не вдаваться в сложную математику я просто перебрал все коэффициенты с шагом в 0.01 для всех формул и это заняло около месяца на нескольких домашних компьютерах.
Самой точной оказывалась формула SMOG (Simple Measure of Gobbledygook) с адаптированными коэффициентами поэтому она и является базовой в оценке
plainrussian.ru.
Всё это было более 7 лет назад, сам код можно увидеть по ссылке на Github [2]. Сейчас его надо переработать чтобы лучше учитывать определение предложений, лучше понимать бюрократические тексты (нужна отдельная шкала) и ещё многое другое до чего постепенно "доходят руки".
Ссылки:
[1]
https://plainrussian.ru[2]
https://github.com/infoculture/plainrussian#plainlanguage #plainrussian