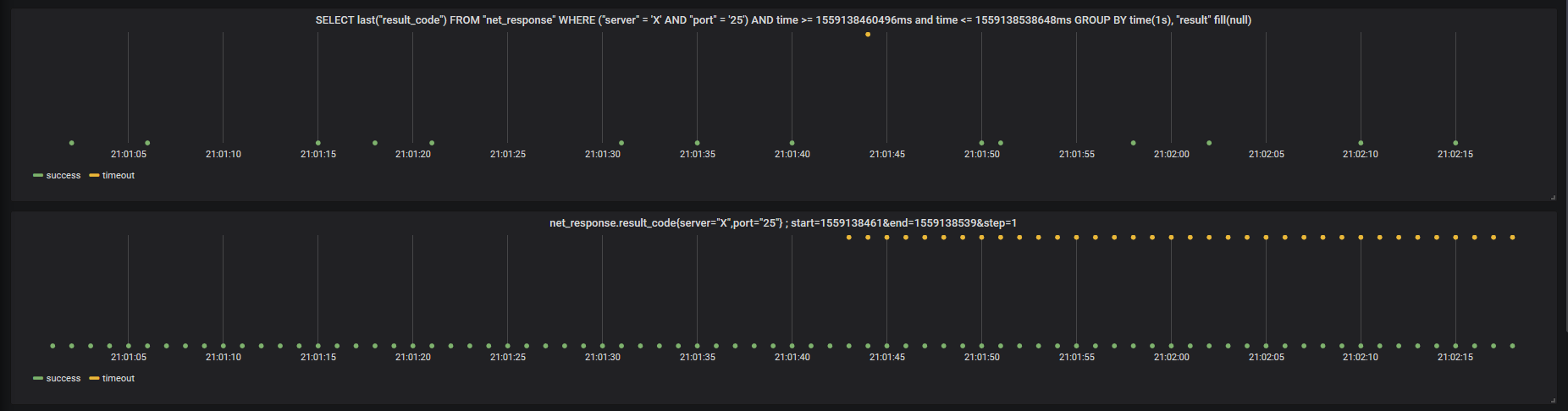
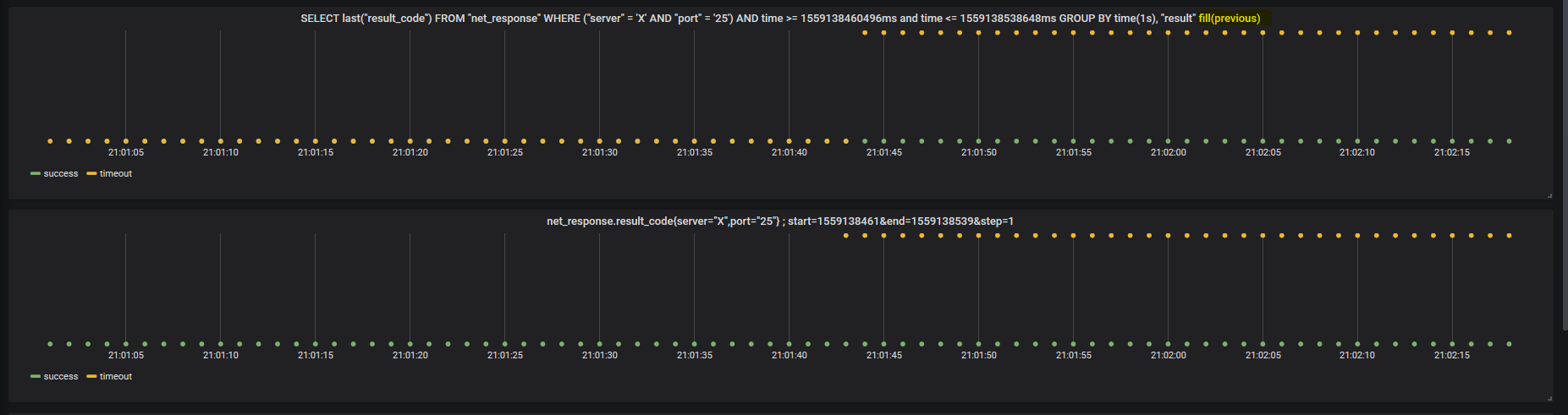
TF
docker run -dit --name victoriametric-new -p 8428:8428 --restart on-failure:3 -http.disableResponseCompression valyala/victoria-metricsтолько так получилось запустить
Size: a a a
TF
docker run -dit --name victoriametric-new -p 8428:8428 --restart on-failure:3 -http.disableResponseCompression valyala/victoria-metricsD
AV
root@px4-glaber / # docker run -it --rm --name victoriametric \
> -p 8428:8428 \
> --restart on-failure:3 \
> --retentionPeriod 1 \
> --http.disableResponseCompression \
> --loggerLevel ERROR \
> --memory.allowedPercent 30 \
> valyala/victoria-metrics:latest
unknown flag: --retentionPeriod
See 'docker run --help'.
root@px4-glaber / # ^C
root@px4-glaber / # docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
root@px4-glaber / # docker run -it --rm --name victoriametric \
> -p 8428:8428 \
> --restart on-failure:3 \
> -retentionPeriod 1 \
> -http.disableResponseCompression \
> -loggerLevel ERROR \
> -memory.allowedPercent 30 \
> valyala/victoria-metrics:latest
unknown shorthand flag: 'r' in -retentionPeriod
See 'docker run --help'.
valyala/victoria-metrics:latest. Перед ним идут флаги докера :)TF
valyala/victoria-metrics:latest. Перед ним идут флаги докера :)yL
VP
ВС
s
yL
{__name__="Cisco-IOS-XR-infra-statsd-oper:infra-statistics/interfaces/interface/latest/generic-counters.bytes-sent"}measurement.field для telegraf/influx данных.measurement, как раньше, шла в label, а field - в имя метрики, такого паровоза бы не было.Server: [http://10.xx.xx.xx:8428], wkid 0, writing 570 points in db: telemetry
(prec: [ms], consistency: [], retention: [])
Cisco-IOS-XR-wdsysmon-fd-oper:system-monitoring/cpu-utilization,EncodingPath=Cisco-IOS-XR-wdsysmon-fd-oper:system-monitoring/cpu-utilization,Producer=xxxxx,node-name=0/0/CPU0 total-cpu-fifteen-minute=3i,total-cpu-five-minute=3i,total-cpu-one-minute=3i 1559204774467000000
EG
TF
TF
EG
AV
AV
measurement.field для telegraf/influx данных.measurement, как раньше, шла в label, а field - в имя метрики, такого паровоза бы не было.Server: [http://10.xx.xx.xx:8428], wkid 0, writing 570 points in db: telemetry
(prec: [ms], consistency: [], retention: [])
Cisco-IOS-XR-wdsysmon-fd-oper:system-monitoring/cpu-utilization,EncodingPath=Cisco-IOS-XR-wdsysmon-fd-oper:system-monitoring/cpu-utilization,Producer=xxxxx,node-name=0/0/CPU0 total-cpu-fifteen-minute=3i,total-cpu-five-minute=3i,total-cpu-one-minute=3i 1559204774467000000
yL
Explore в графане даже '-' в имени label не переваривает.curl --user 'victoria:victoria' -g --url 'http://lmon:8428/api/v1/series?' --data-urlencode 'match[]={interface-name="Bundle-Ether3"}'
{"status":"error","errorType":"422","error":"cannot parse \"{interface-name=\\\"Bundle-Ether3\\\"}\": tagFilterExpr: unexpected token \"-\"; want \"=\", \"!=\", \"=~\", \"!~\", \",\", \"}\"; unparsed data: \"-name=\\\"Bundle-Ether3\\\"}\""}ВС
[[processors.regex]]
namepass = ["measurement"]
[[processors.regex.fields]]
key = "EncodingPath"
pattern = "^.Cisco-IOS-XR-wdsysmon-fd-oper:system-monitoring/cpu-utilization$"
replacement = "cpu"
yL
[[processors.regex]]
namepass = ["measurement"]
[[processors.regex.fields]]
key = "EncodingPath"
pattern = "^.Cisco-IOS-XR-wdsysmon-fd-oper:system-monitoring/cpu-utilization$"
replacement = "cpu"
ВС