



ДZ
Size: a a a
2020 October 05
ДZ
Все в доке подробно описано
US
Вот, не нашел как раз это. Спасибо большое всем, кто уделил время
M
Необходима разработка навыка для Алисы, аналогичного Tuya Smart, Digma, Elary. Все предложения интересны.
ДZ
Здравствуйте! А результаты премии Алисы сегодня будут?
Привет! Да, должны)
NK
Премия Алисы за сентябрь
На календаре 5 октября — время подвести итоги сентябрьской премии Алисы. Мы рады, что количество и качество навыков растет от месяца к месяцу, а значит мы на верном пути.
Сделаем Алису умнее! Вот наши победители:
Первое место — 100 000 рублей и проморазмещение в каталоге Алисы
Море слов — Проверь свою эрудицию! Собери только правильные слова из заданных букв. Алиса будет помогать тебе двигаться в правильном направлении.
Второе место — 35 000 рублей и проморазмещение в каталоге Алисы
Пьяный Аристотель — Аристотель называет число и просит вас прибавить или отнять от него что-нибудь. Ваша задача — назвать результат.
Третье место — 15 000 рублей и проморазмещение в каталоге Алисы
Угадай воинское звание — Угадывай воинские звания в российской армии по погонам сухопутных войск.
Благодарим разработчиков за участие! Если ваш навык впервые был отобран в шорт-лист номинантов — приглашаем вновь побороться за призовое место.
Тем временем Премия Алисы продолжается, а это значит, что мы с нетерпением ждем ваших новых навыков.
На календаре 5 октября — время подвести итоги сентябрьской премии Алисы. Мы рады, что количество и качество навыков растет от месяца к месяцу, а значит мы на верном пути.
Сделаем Алису умнее! Вот наши победители:
Первое место — 100 000 рублей и проморазмещение в каталоге Алисы
Море слов — Проверь свою эрудицию! Собери только правильные слова из заданных букв. Алиса будет помогать тебе двигаться в правильном направлении.
Второе место — 35 000 рублей и проморазмещение в каталоге Алисы
Пьяный Аристотель — Аристотель называет число и просит вас прибавить или отнять от него что-нибудь. Ваша задача — назвать результат.
Третье место — 15 000 рублей и проморазмещение в каталоге Алисы
Угадай воинское звание — Угадывай воинские звания в российской армии по погонам сухопутных войск.
Благодарим разработчиков за участие! Если ваш навык впервые был отобран в шорт-лист номинантов — приглашаем вновь побороться за призовое место.
Тем временем Премия Алисы продолжается, а это значит, что мы с нетерпением ждем ваших новых навыков.
2
Поздравляю победителей!
A
ID:0
Премия Алисы за сентябрь
На календаре 5 октября — время подвести итоги сентябрьской премии Алисы. Мы рады, что количество и качество навыков растет от месяца к месяцу, а значит мы на верном пути.
Сделаем Алису умнее! Вот наши победители:
Первое место — 100 000 рублей и проморазмещение в каталоге Алисы
Море слов — Проверь свою эрудицию! Собери только правильные слова из заданных букв. Алиса будет помогать тебе двигаться в правильном направлении.
Второе место — 35 000 рублей и проморазмещение в каталоге Алисы
Пьяный Аристотель — Аристотель называет число и просит вас прибавить или отнять от него что-нибудь. Ваша задача — назвать результат.
Третье место — 15 000 рублей и проморазмещение в каталоге Алисы
Угадай воинское звание — Угадывай воинские звания в российской армии по погонам сухопутных войск.
Благодарим разработчиков за участие! Если ваш навык впервые был отобран в шорт-лист номинантов — приглашаем вновь побороться за призовое место.
Тем временем Премия Алисы продолжается, а это значит, что мы с нетерпением ждем ваших новых навыков.
На календаре 5 октября — время подвести итоги сентябрьской премии Алисы. Мы рады, что количество и качество навыков растет от месяца к месяцу, а значит мы на верном пути.
Сделаем Алису умнее! Вот наши победители:
Первое место — 100 000 рублей и проморазмещение в каталоге Алисы
Море слов — Проверь свою эрудицию! Собери только правильные слова из заданных букв. Алиса будет помогать тебе двигаться в правильном направлении.
Второе место — 35 000 рублей и проморазмещение в каталоге Алисы
Пьяный Аристотель — Аристотель называет число и просит вас прибавить или отнять от него что-нибудь. Ваша задача — назвать результат.
Третье место — 15 000 рублей и проморазмещение в каталоге Алисы
Угадай воинское звание — Угадывай воинские звания в российской армии по погонам сухопутных войск.
Благодарим разработчиков за участие! Если ваш навык впервые был отобран в шорт-лист номинантов — приглашаем вновь побороться за призовое место.
Тем временем Премия Алисы продолжается, а это значит, что мы с нетерпением ждем ваших новых навыков.
Присоединяюсь к поздравлениям 👍👍👍
DM
Поздравляю победителей!! 👍👍🧑💻
A
ID:0
Премия Алисы за сентябрь
На календаре 5 октября — время подвести итоги сентябрьской премии Алисы. Мы рады, что количество и качество навыков растет от месяца к месяцу, а значит мы на верном пути.
Сделаем Алису умнее! Вот наши победители:
Первое место — 100 000 рублей и проморазмещение в каталоге Алисы
Море слов — Проверь свою эрудицию! Собери только правильные слова из заданных букв. Алиса будет помогать тебе двигаться в правильном направлении.
Второе место — 35 000 рублей и проморазмещение в каталоге Алисы
Пьяный Аристотель — Аристотель называет число и просит вас прибавить или отнять от него что-нибудь. Ваша задача — назвать результат.
Третье место — 15 000 рублей и проморазмещение в каталоге Алисы
Угадай воинское звание — Угадывай воинские звания в российской армии по погонам сухопутных войск.
Благодарим разработчиков за участие! Если ваш навык впервые был отобран в шорт-лист номинантов — приглашаем вновь побороться за призовое место.
Тем временем Премия Алисы продолжается, а это значит, что мы с нетерпением ждем ваших новых навыков.
На календаре 5 октября — время подвести итоги сентябрьской премии Алисы. Мы рады, что количество и качество навыков растет от месяца к месяцу, а значит мы на верном пути.
Сделаем Алису умнее! Вот наши победители:
Первое место — 100 000 рублей и проморазмещение в каталоге Алисы
Море слов — Проверь свою эрудицию! Собери только правильные слова из заданных букв. Алиса будет помогать тебе двигаться в правильном направлении.
Второе место — 35 000 рублей и проморазмещение в каталоге Алисы
Пьяный Аристотель — Аристотель называет число и просит вас прибавить или отнять от него что-нибудь. Ваша задача — назвать результат.
Третье место — 15 000 рублей и проморазмещение в каталоге Алисы
Угадай воинское звание — Угадывай воинские звания в российской армии по погонам сухопутных войск.
Благодарим разработчиков за участие! Если ваш навык впервые был отобран в шорт-лист номинантов — приглашаем вновь побороться за призовое место.
Тем временем Премия Алисы продолжается, а это значит, что мы с нетерпением ждем ваших новых навыков.
Поздравляю победителей!
AL
>> Тем временем Премия Алисы продолжается
а в полных правилах - это был последний этап))
а в полных правилах - это был последний этап))
ДZ
>> Тем временем Премия Алисы продолжается
а в полных правилах - это был последний этап))
а в полных правилах - это был последний этап))
Еще распишут)
2
Может вернёмся к старым правилам?) Три по сто было интереснее...
2
Предлагаю голосовать)
ПА
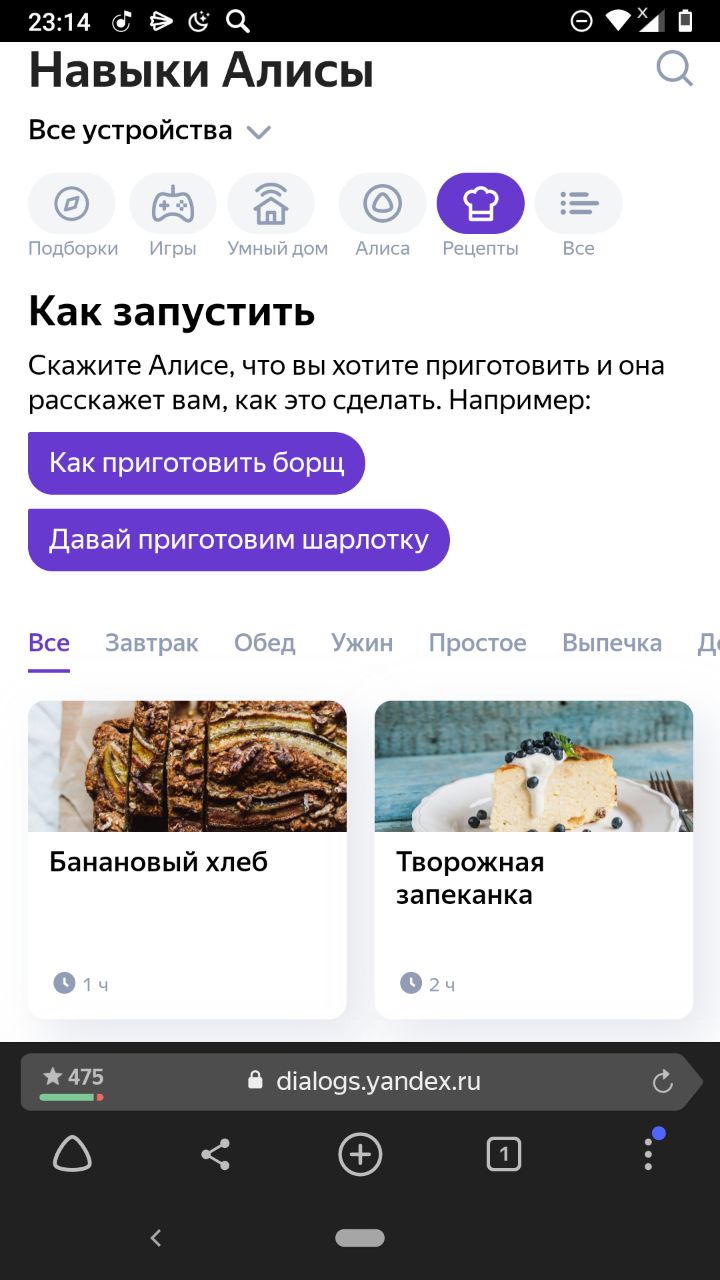
Все пропустили появление нового раздела в навыках "рецепты"
DD
Всем привет!
Я тут немножко запутался в нормализациях входного текста, которые делаются в Алисе и в частности в NLU. Может кто-нибудь объяснить мне логику или сослаться на доку, где она объяснена?
1) Говорю "купи тысячу пятьсот грамм пиццы", на экране пишется "купи 1500 грамм пиццы", в NLU токены ['купи', '1500', 'грамм', 'пиццы'], а вот текстовый слот "количество" из моей грамматики внезапно заполняется значением 'тысячу пятьсот грамм'. Как так? Откуда эти текстовые токены вообще взялись?
2) Говорю 'закажи одна целая пять десятых килограмма', вижу на экране 'закажи 1,5 кг', при этом поле nlu.command равно 'закажи 1,5 килограмма'. Окей, бог с ним с написанием, "кг" или "килограммы". Но при этом в NLU токены внезапно оказываются ['закажи', '1', '5', 'кг'], запятая потерялась, и восстановить число уже проблемно. А в текстовый слот, отвечающий за количество, попадает текст 'одна целая пять десятых килограмма', не похожий ни на текст с экрана, ни на command, ни на токены.
Как, в этом, вообще, разобраться?) 🤦🏼♂️
В идеальном мире, кажется, массив tokens был бы равен полю command, разбитому по пробелам, а все текстовые слоты были бы его подстроками. По крайней мере, мне это кажется логичным. А вот логику того, что приходит в запросе, я пока не уловил.
Я тут немножко запутался в нормализациях входного текста, которые делаются в Алисе и в частности в NLU. Может кто-нибудь объяснить мне логику или сослаться на доку, где она объяснена?
1) Говорю "купи тысячу пятьсот грамм пиццы", на экране пишется "купи 1500 грамм пиццы", в NLU токены ['купи', '1500', 'грамм', 'пиццы'], а вот текстовый слот "количество" из моей грамматики внезапно заполняется значением 'тысячу пятьсот грамм'. Как так? Откуда эти текстовые токены вообще взялись?
2) Говорю 'закажи одна целая пять десятых килограмма', вижу на экране 'закажи 1,5 кг', при этом поле nlu.command равно 'закажи 1,5 килограмма'. Окей, бог с ним с написанием, "кг" или "килограммы". Но при этом в NLU токены внезапно оказываются ['закажи', '1', '5', 'кг'], запятая потерялась, и восстановить число уже проблемно. А в текстовый слот, отвечающий за количество, попадает текст 'одна целая пять десятых килограмма', не похожий ни на текст с экрана, ни на command, ни на токены.
Как, в этом, вообще, разобраться?) 🤦🏼♂️
В идеальном мире, кажется, массив tokens был бы равен полю command, разбитому по пробелам, а все текстовые слоты были бы его подстроками. По крайней мере, мне это кажется логичным. А вот логику того, что приходит в запросе, я пока не уловил.
2020 October 06
DD
И смежный вопрос к участникам чата: как вы вообще юнит-тестируете извлечение слотов яндексовскими грамматиками?
С
Всем привет. А можно в навыках использовать несколько голосов?