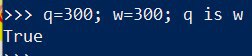VN
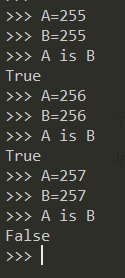
ну если бы я реально где-то на подобное завязывался, то пошел сначала PEP искать, где это явно указано.
Да, это конечно правильный подход.
Вообще услышал в каком-то видосе-лекции... рассказывалось вроде как о заложенном поведении языка.
Вообще услышал в каком-то видосе-лекции... рассказывалось вроде как о заложенном поведении языка.