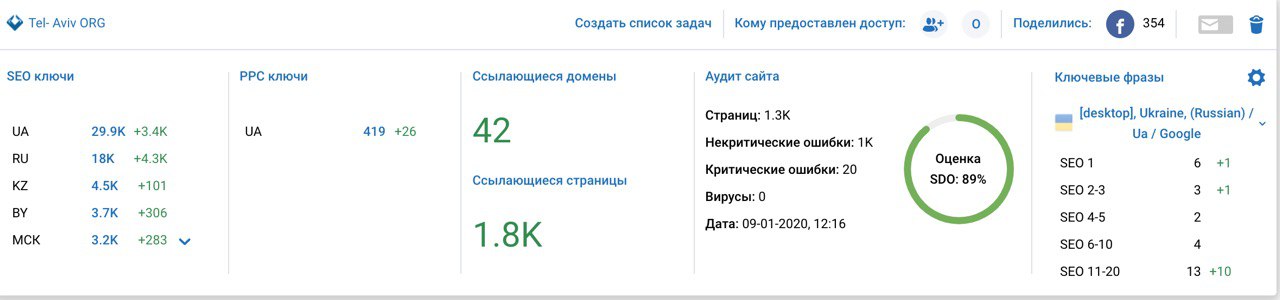
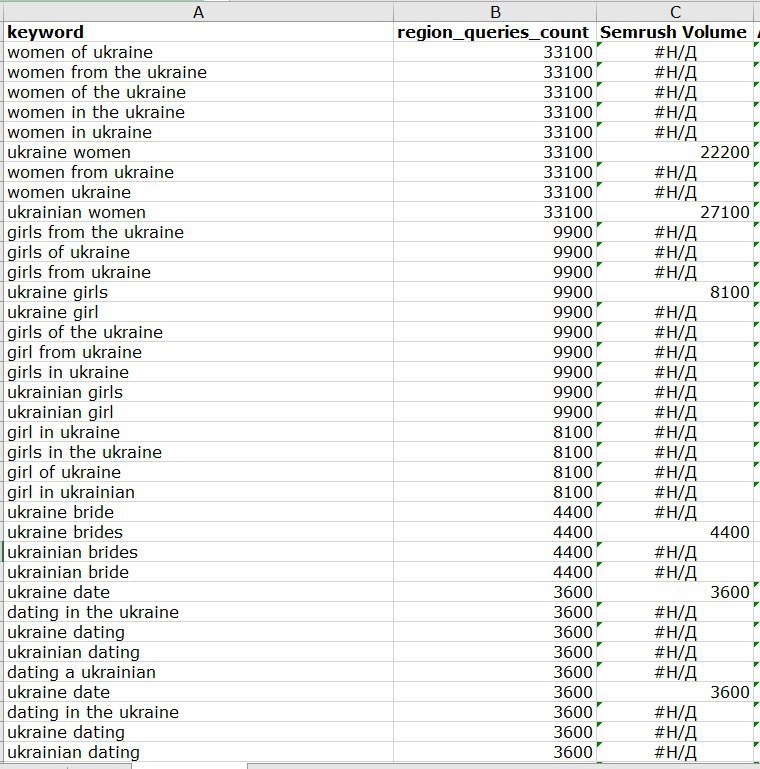
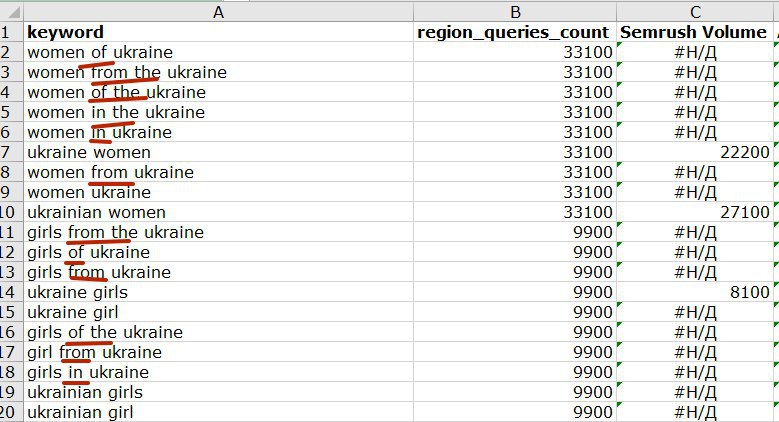
Я кажется уже писал, но такое впечатление, что serpstat генерирует "варианты написания запроса" и присваивает им частность, равную первоначальному написанию. Кусочек скрина сверки данных; я сейчас не про то, у кого правильно или достоверно, а про то, что для того, чтобы выбрать запрос, который с большей вероятностью будет "реальным" и с реальной частотой - приходится сводить данные по нескольким сервисам частотностей.