



AR
а код неправильный, нельзя все подряд хедеры совать, как минимум Content-Length нельзя совать вручную никогда
Size: a a a
AR
АМ
АМ
АМ
curl -k 'https://yweb.ymcaboston.org/SpiritWeb/SearchClass' -H 'Content-Type: application/x-www-form-urlencoded' -H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.17 Safari/537.36' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' -H 'Referer: https://yweb.ymcaboston.org/SpiritWeb/SearchClass' --data '_EXECEVENT=ONSEARCH&BRANCH_IDENTIFIER=&SELECT_AGE=&PPG_PROGRAM_IDENTIFIER=&POF_CLASS_IDENTIFIER=&_BRIEF_DESC=&SELECT_MONTH=&_CLASS_OFFERING_IDENTIFIER=&SORTBY=AGE' --compressedМ
МС
AB
AB
AB
МС
AB
МС
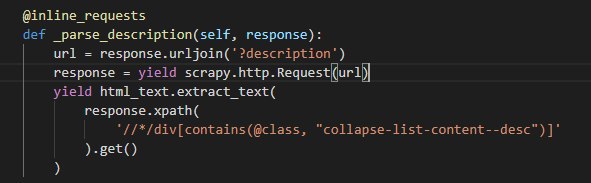
om inline_requests import inline_requests
from scrapy import Spider, Request
class MySpider(Spider):
name = 'myspider'
start_urls = ['http://httpbin.org/html']
@inline_requests
def parse(self, response):
urls = [response.url]
for i in range(10):
next_url = response.urljoin('?page=%d' % i)
try:
next_resp = yield Request(next_url)
urls.append(next_resp.url)
except Exception:
self.logger.info("Failed request %s", i, exc_info=True)
yield {'urls': urls}
МС
AB
AB
МС
МС
AB
AB