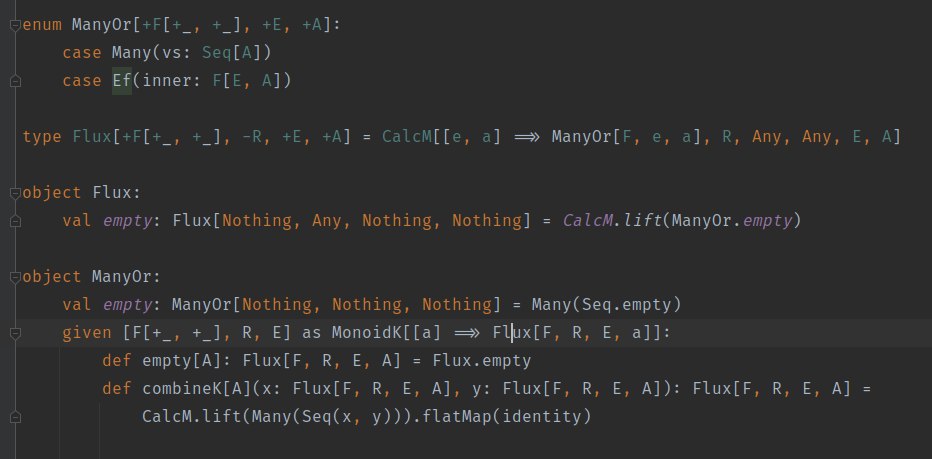
Я сформулировал, что не так. У меня монолит, кода очень много. Очень много крутится вокруг одной-двух таблиц с разными вариациями запросов. Т.е в одном бизнес-логики месте надо обновить только одно поле, в другом - два других, в третьем - третье. С объединениями этих дао (репозиториями) та же история - в одном месте логики надо достать сущность №1, в другом - №1 и 2, в третьем №1, 2 и 3, ещё в одном - постобработать после того, как достал из БД. Доставать постоянно один и тот же набор данных со всеми сущностями нельзя, это оверхед. В результате API таких репозиториев, как ты предлагаешь, будет супер-бойлерплейтным и загрязненным этими вариациями