



IG
Size: a a a
2020 January 17

2020 January 18
АА
Даже он пишет что некоторые вещи нужно делать только после одобрения folks которые отвечают за какое-то узкое место в ядре. Я к тому что нет одного человека который бы понимал как надо сделать это правильно и решить данную проблему. Ну и раскритиковал код earlyoom :)
Решить проблему правильно - это отключить оверкоммит памяти. Ядерный киллер - это в том числе тоже костыль.
АА
Может ты до сих пор не понял что текущее, предложенное решение может создать больше проблем чем решить. Давай ты почитаешь сначала хотя бы что Леня пишет, а потом послушаем уже мнение других экспертов
Hmm, are we sure this is something we want to have in the default
install? Is the code really good enough for that?
Looking at the sources very superficially I see a couple of problems:
1. Waking up all the time in 100ms intervals? We generally try to
avoid waking the CPU up all the time if nothing happens. Saving
power and things.
2. New code using system() in the year 2020? Really?
3. Fixed size buffers and implicit, undetected, truncation of strings
at various places (for example, when formatting the shell string to
pass to system()).
But more importantly: are we sure this actually operates the way we
should? i.e. PSI is really what should be watched. It is not
interesting who uses how much memory and triggering kills on
that. What matters is to detect when the system becomes slow due to
that, i.e. *latencies* introduced due to memory pressure and that's
what PSI is about, and hence what should be used.
But even if we'd ignore that in order fight latencies one should watch
latencies: OOM killing per process is just not appropriate on a
systemd system: all our system services (and a good chunk of our user
services too) are sorted neatly into cgroups, and we really should
kill them as a whole and not just individual processes inside
them. systemd manages that today, and makes exceptions configurable
via OOMPolicy=, and with your earlyoom stuff you break that.
This looks like second guessing the kernel memory management folks at
a place where one can only lose, and at the time breaking correct OOM
reporting by the kernel via cgroups and stuff.
Also: what precisely is this even supposed to do? Replace the
algorithm for detecting *when* to go on a kill rampage? Or actually
replace the algorithm selecting *what* to kill during a kill rampage?
If it's the former (which the name of the project suggests,
_early_oom)), then at the most basic the tool should let the kernel do
the killing, i.e. "echo f > /proc/sysrq-trigger". That way the
reporting via cgroups isn't fucked, and systemd can still do its
thing, and the kernel can kill per cgroup rather than per process...
Anyway, this all sounds very very fishy to me. Not thought to the end,
and I am pretty sure this is something the kernel memory management
folks should give a blessing to. Second guessing the kernel like that
is just a bad idea if you ask me.
I mean, yes, the OOM killer might not be that great currently, but
this sounds like something to fix in kernel land, and if that doesn't
work out for some reason because kernel devs can't agree, then do it
as fallback in userspace, but with sound input from the kernel folks,
and the blessing of at least some of the kernel folks.
Lennart
Hmm, are we sure this is something we want to have in the default
install? Is the code really good enough for that?
Looking at the sources very superficially I see a couple of problems:
1. Waking up all the time in 100ms intervals? We generally try to
avoid waking the CPU up all the time if nothing happens. Saving
power and things.
2. New code using system() in the year 2020? Really?
3. Fixed size buffers and implicit, undetected, truncation of strings
at various places (for example, when formatting the shell string to
pass to system()).
But more importantly: are we sure this actually operates the way we
should? i.e. PSI is really what should be watched. It is not
interesting who uses how much memory and triggering kills on
that. What matters is to detect when the system becomes slow due to
that, i.e. *latencies* introduced due to memory pressure and that's
what PSI is about, and hence what should be used.
But even if we'd ignore that in order fight latencies one should watch
latencies: OOM killing per process is just not appropriate on a
systemd system: all our system services (and a good chunk of our user
services too) are sorted neatly into cgroups, and we really should
kill them as a whole and not just individual processes inside
them. systemd manages that today, and makes exceptions configurable
via OOMPolicy=, and with your earlyoom stuff you break that.
This looks like second guessing the kernel memory management folks at
a place where one can only lose, and at the time breaking correct OOM
reporting by the kernel via cgroups and stuff.
Also: what precisely is this even supposed to do? Replace the
algorithm for detecting *when* to go on a kill rampage? Or actually
replace the algorithm selecting *what* to kill during a kill rampage?
If it's the former (which the name of the project suggests,
_early_oom)), then at the most basic the tool should let the kernel do
the killing, i.e. "echo f > /proc/sysrq-trigger". That way the
reporting via cgroups isn't fucked, and systemd can still do its
thing, and the kernel can kill per cgroup rather than per process...
Anyway, this all sounds very very fishy to me. Not thought to the end,
and I am pretty sure this is something the kernel memory management
folks should give a blessing to. Second guessing the kernel like that
is just a bad idea if you ask me.
I mean, yes, the OOM killer might not be that great currently, but
this sounds like something to fix in kernel land, and if that doesn't
work out for some reason because kernel devs can't agree, then do it
as fallback in userspace, but with sound input from the kernel folks,
and the blessing of at least some of the kernel folks.
Lennart
"we really should
kill them as a whole and not just individual processes" - во многих случаях это не оптимальное решение. Пункты 2 и 3 не имеют отношения к дефолтам. Пункт 1: на самом деле интервал 1 сек, а не 0.1 сек.
kill them as a whole and not just individual processes" - во многих случаях это не оптимальное решение. Пункты 2 и 3 не имеют отношения к дефолтам. Пункт 1: на самом деле интервал 1 сек, а не 0.1 сек.
ВТ
В 5.4.10 починили тачпад на моем ноуте (он подключен через i2c и после пробуждения не работал пока модул ядра i2c_hid не перезапустишь) теперь после пробуждения работает все кроме прокрутки двумя пальцами, опять же если перезапустить i2c_hid прокрутка работает
B
В 5.4.10 починили тачпад на моем ноуте (он подключен через i2c и после пробуждения не работал пока модул ядра i2c_hid не перезапустишь) теперь после пробуждения работает все кроме прокрутки двумя пальцами, опять же если перезапустить i2c_hid прокрутка работает
Очень информативное сообщение. Все владельцы "твоего ноута" аплодируют стоя. 👏😎
ВТ
DELL Inspiron 5391
I
Привет! Кто-то знает какая команда запуска у vim?
I
DELL Inspiron 5391
Я задам наитупейший вопрос:
А в настройках в разделе "Устройства" смотрели настройки?
А в настройках в разделе "Устройства" смотрели настройки?
I
DELL Inspiron 5391
Какая оболочка стоит?
🌝
Привет! Кто-то знает какая команда запуска у vim?
Очень толсто
I
Очень толсто
Что?
🌝
Что?
Троллинг толстый очень.
YS
Очень толсто
"Тебя как, Федя, зовут?" :D
I
Троллинг толстый очень.
А, не, я про сочентания клавиш.
Как забиндить. Вроде, ввел vim, а оно не запускается
Как забиндить. Вроде, ввел vim, а оно не запускается
ВТ
Я задам наитупейший вопрос:
А в настройках в разделе "Устройства" смотрели настройки?
А в настройках в разделе "Устройства" смотрели настройки?
Да, gnome, настройка стоит
I
Да, gnome, настройка стоит
Оке, а gnome-tweak-tool качали?
I
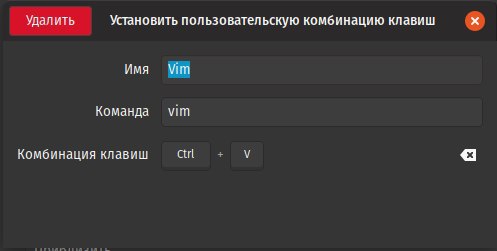
Я про это
B
Ну введи в терминале which vim и полученный ответ используй...
I
Ок, спасибо
ВТ
Прокрутка работает, но после просыпания - нет. Если перезагрузить модуль ядра i2c_hid прокрутка снова работает