


AS
меня вот это смутило
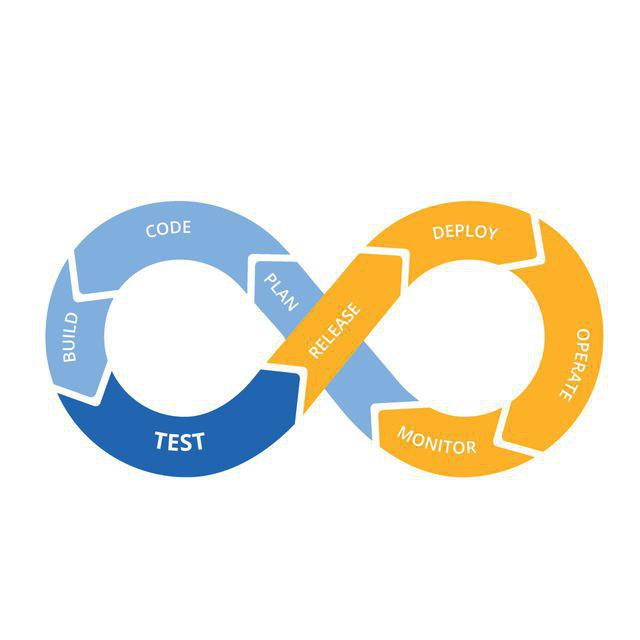
Однако перед тем, как приступить к её обзору, стоит упомянуть, что в проекте используется standalone Redis, поскольку кластерное решение на основе Sentinel сильно уступает по задержкам (latency).
сделай тестовое развертывание, да замерь задержки, потом по факту тебе и будет видно - устраивают цифры или нет
