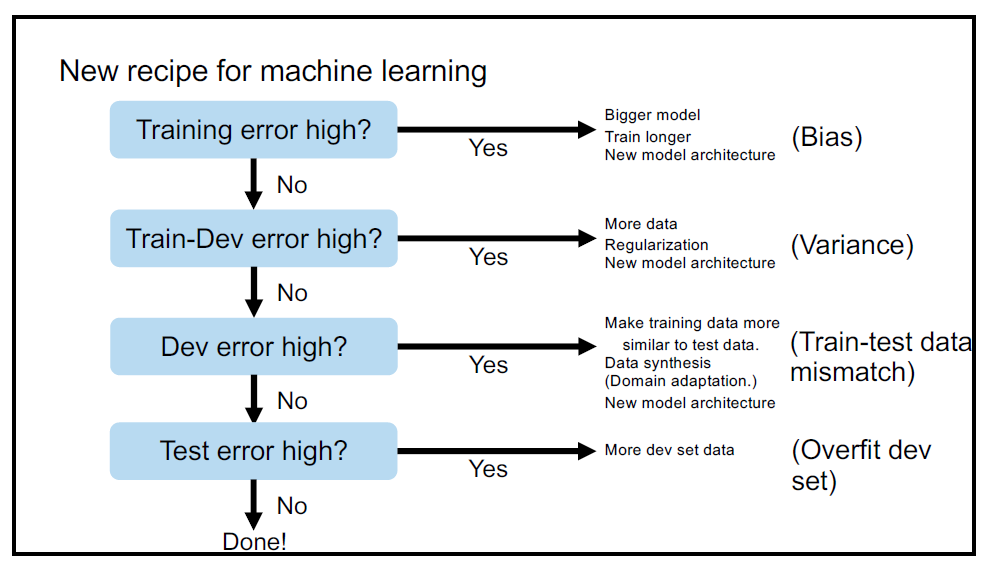
может и так, но это непонятно.
пункты в этой схеме последовательны, если ошибка в первом шаге, то её нужно исправлять в первую очередь, чтобы прояснить что ещё не так.
если же считаешь, что training error у тебя нормальный (можешь попробовать ручной анализ ошибок провести -- реально там сложные случаи или сеть вообще тупит), то у тебя начинает пункт 2 работать. у тебя 30%-10%, т.е. большая разница между train и dev. Что говорит о том, что данные сильно разные в train и dev, и значит, что если всё ок с training set, то нужно увеличивать или по-другому выбирать dev set.