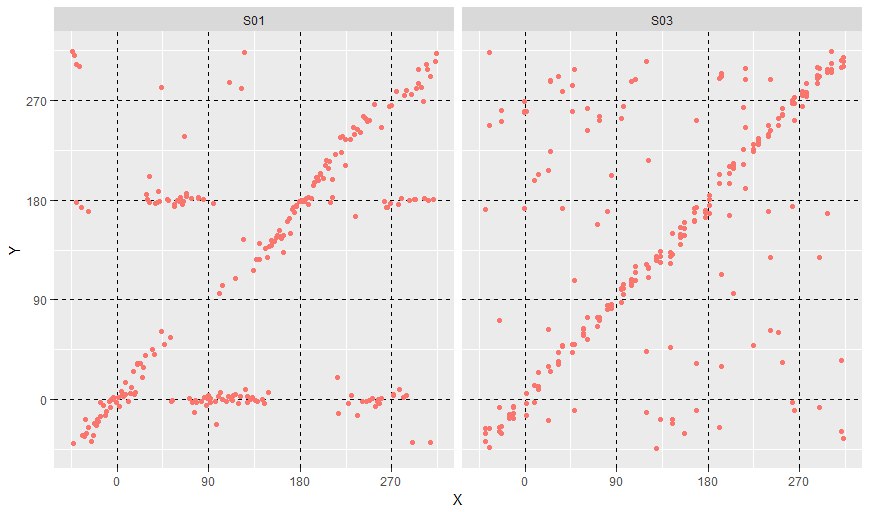
вы имеете в виду обычную регрессию? тут же модели альтернативные, а не взаимодополняющие
ну то есть y = 0 и y = 180 - как тут регрессию сделать?
значение каждой модели на объекте - это св-во объекта
И нужно построить новую регрессию, где отклик - это значение с графики, а св-ва - это значения, которые выдает вам ваши модели, и в общем то все равно, дополняющие они или нет, единственное с чем нужно побороться, так это с мультиколлинеарностью и исключить некоторые модели. Например, модель y = 0 всегда придется исключить, так как ее вклад в любой значение неизмерим